
Woningbouwplannen genoeg: maar halen we onze doelen?
Met de lancering van de Nationale Woningbouwkaart werd opnieuw zichtbaar hoeveel woningbouwplannen er in Nederland zijn. De kaart laat zien dat er een enorme planvoorraad beschikbaar is. Op papier lijken de aantallen ruim voldoende om aan de woningbouwopgave te voldoen.
Tegelijkertijd weten we allemaal dat plannen nog geen woningen zijn. Projecten lopen vertraging op. Procedures duren langer dan verwacht. Netcongestie, stikstof, capaciteitstekorten en financiële haalbaarheid zorgen ervoor dat niet ieder plan volgens planning gerealiseerd wordt. Daardoor verschuift de aandacht langzaam maar zeker van een andere vraag.
Niet: hoeveel plannen hebben we?
Maar: gaan we onze doelen ook daadwerkelijk halen?
Een nieuwe werkelijkheid voor gemeenten
Die vraag wordt steeds relevanter. Met de Wet regie op de volkshuisvesting krijgen gemeenten de verplichting om uiterlijk op 1 juli 2027 een volkshuisvestingsprogramma vast te stellen. In zo’n programma leggen gemeenten vast welke doelen zij willen bereiken op het gebied van woningbouw, betaalbaarheid en doelgroepen.
Dat betekent dat het niet langer voldoende is om alleen inzicht te hebben in projecten en aantallen. Gemeenten zullen ook moeten kunnen volgen of de uitvoering nog in lijn ligt met de gemaakte afspraken.
Maar het volkshuisvestingsprogramma staat niet op zichzelf.
Gemeenten sturen inmiddels op een groeiend aantal doelstellingen. Denk aan afspraken uit de Woondeals, prestatieafspraken met woningcorporaties, doelstellingen voor sociale huur en betaalbare woningen, subsidievoorwaarden en lokale beleidsdoelen. In veel gevallen bestaan deze afspraken naast elkaar en hebben ze allemaal betrekking op dezelfde woningbouwprojecten.
Daardoor ontstaat een nieuwe uitdaging: hoe houd je overzicht over al die doelstellingen en hoe weet je of je nog op koers ligt?

Afbeelding 1: Nationale Woningbouwkaart
De vraag verandert
De afgelopen jaren hebben veel gemeenten geïnvesteerd in woningbouwmonitoring. Projecten zijn geregistreerd, planningen zijn inzichtelijk gemaakt en rapportages kunnen relatief eenvoudig worden opgesteld. Dat is een belangrijke stap geweest. Maar in gesprekken met gemeenten merken we dat de vraag verandert. Steeds vaker horen we vragen als:
- Halen we de afspraken uit de Woondeal?
- Liggen we nog op koers voor 30% sociale huur?
- Welke projecten dragen bij aan onze prestatieafspraken met corporaties?
- Wat gebeurt er als een belangrijk project twee jaar vertraging oploopt?
- Welke alternatieven hebben we als een project afvalt?
- Op welke projecten kunnen we nog daadwerkelijk sturen?
Dat zijn geen monitoringsvragen meer. Het zijn sturingsvragen.
Monitoren is niet hetzelfde als sturen
Een monitor vertelt wat er gebeurt. Een stuurinstrument helpt bepalen wat er moet gebeuren. Dat verschil lijkt klein, maar is fundamenteel.
Wanneer een gemeente ziet dat er 500 woningen minder gerealiseerd dreigen te worden dan gepland, ontstaat direct een vervolgvraag. Welke projecten kunnen dat tekort opvangen? Zijn er alternatieve locaties beschikbaar? Moeten bepaalde projecten voorrang krijgen? En wat betekent dat voor andere beleidsdoelen? Juist die vertaalslag van projectinformatie naar bestuurlijke keuzes wordt steeds belangrijker.
Daarbij gaat het niet alleen om aantallen woningen. Ook kwalitatieve doelstellingen spelen een steeds grotere rol. Denk aan sociale huur, middenhuur, betaalbare koopwoningen, woonwagenlocaties of specifieke doelgroepen. Een project kan bijdragen aan meerdere doelstellingen tegelijk. Tegelijkertijd kan het uitvallen van één project gevolgen hebben voor verschillende afspraken en programma’s.
Om daarop te kunnen sturen is meer nodig dan een lijst met projecten.

Afbeelding 2: van monitoren naar sturen
Van projecten naar doelstellingen
Tijdens een recente werksessie met gemeenten zagen we dat vrijwel iedere deelnemer met dezelfde uitdaging worstelt. Naast de woningbouwmonitor worden vaak nog aanvullende Excelbestanden bijgehouden voor Woondeals, prestatieafspraken, subsidies en lokale beleidsdoelen. Verschillende afdelingen werken met verschillende overzichten en rapportages. Het gevolg is dat veel tijd wordt besteed aan het verzamelen, controleren en combineren van informatie.
Tegelijkertijd groeit de behoefte aan een integraal beeld. Niet alleen inzicht in projecten, maar inzicht in de relatie tussen projecten en doelstellingen. Welke projecten dragen bij aan welke afspraken? Waar ontstaan risico’s? En welke gevolgen heeft een wijziging in een project voor de totale opgave?
Dat vraagt om een andere manier van kijken naar woningbouwmonitoring.
De eerste stap naar doelgericht sturen: Doelstellingen module
Juist vanuit deze behoefte hebben we binnen Juno de Doelstellingenmodule ontwikkeld. De module bouwt voort op de informatie die al beschikbaar is binnen de woningbouwmonitor. Projecten, woningtypen, statussen en planvoorraad worden gekoppeld aan beleidsdoelen en afspraken.
Daardoor ontstaat een nieuw perspectief.
Gemeenten kunnen niet alleen zien hoeveel woningen er in de planning zitten, maar ook in hoeverre deze bijdragen aan concrete doelstellingen. Denk aan aantallen woningen, percentages sociale huur of andere beleidsmatige KPI’s. Op één plek wordt zichtbaar of de huidige planvoorraad voldoende is om de gestelde doelen te behalen.
Belangrijker nog: de relatie tussen doelstelling en project blijft zichtbaar. Hierdoor ontstaat inzicht in welke projecten daadwerkelijk bijdragen aan het behalen van een doel en waar eventueel ruimte is om bij te sturen.
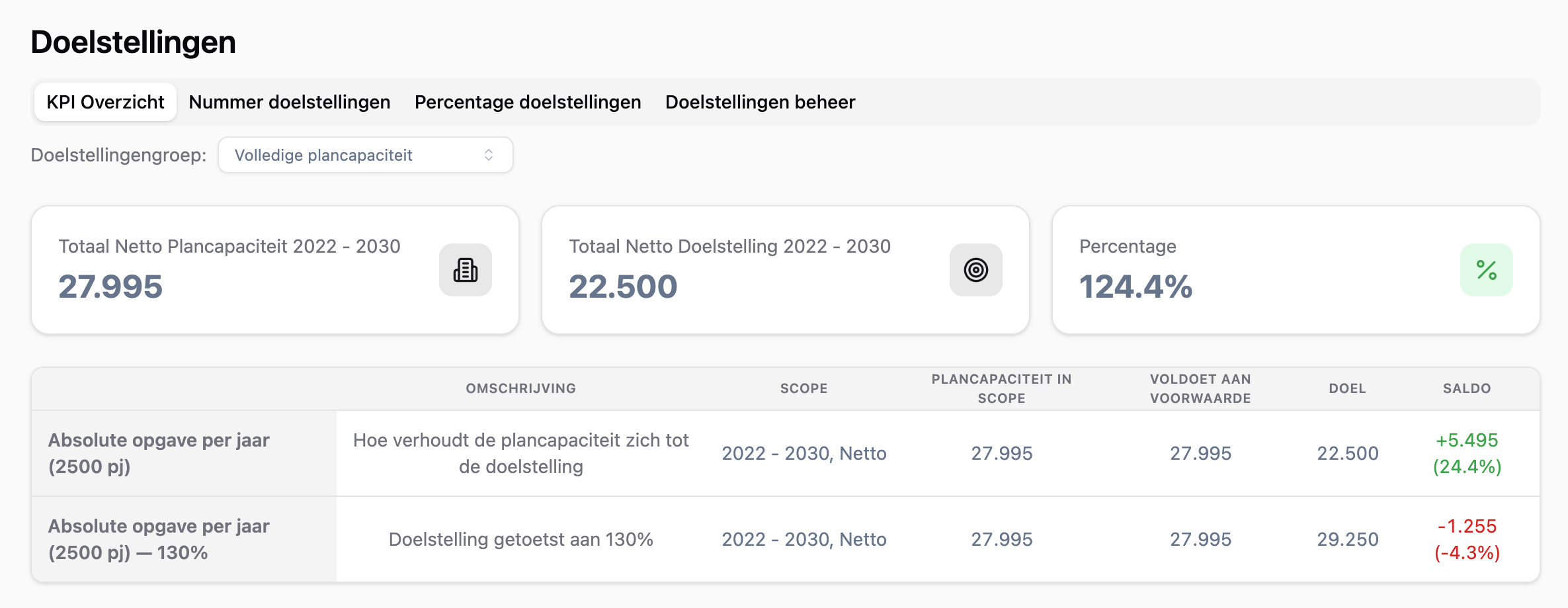
Afbeelding 3: Doelstellingen module
De volgende stap
Wij verwachten dat de ontwikkeling hiermee niet stopt. De volgende vraag dient zich namelijk al aan. Wat gebeurt er als een project vertraagt? Welke gevolgen heeft dat voor de verschillende doelstellingen? En welke alternatieven zijn beschikbaar om toch op koers te blijven?
Daarmee verschuift woningbouwmonitoring opnieuw een stap verder. Van registreren naar monitoren. Van monitoren naar sturen. En uiteindelijk misschien wel naar scenario’s en voorspellende inzichten. Voor gemeenten die de komende jaren aan de slag gaan met hun volkshuisvestingsprogramma, Woondealafspraken en prestatieafspraken wordt dat steeds belangrijker.
Want uiteindelijk gaat het niet om de vraag hoeveel plannen er op papier staan.
Het gaat om de vraag of je de doelen die je met elkaar hebt afgesproken ook daadwerkelijk gaat realiseren.
Zie ook
Webinar
Whitepaper
Blogs
- Van woningbouwmonitor naar sturingsinstrument: wat gemeenten nu nodig hebben
- Iedere gemeente een volkshuisvestingsprogramma. Maar hoe stuur je daarop?
- Het is weer zover: de halfjaarlijkse woningbouwuitvraag
- Waarom woningbouwmonitoring vaak als administratief gedoe voelt (en dat niet hoeft)
- Een toekomstbestendige woningbouw monitor begint bij definities en datakwaliteit
- Het verhaal achter Juno 2.0: een platform opnieuw uitgedacht
- Publieke monitor of publiek-private monitor? Tijd voor helderheid
- Sturen op woningbouw met AI: van datasysteem naar regieplatform
- De Publiek-Private Monitor (PPM)van Juno: één fundament voor versnellingstafels én gemeenten
- Van losse excels naar één cockpit: zo helpt Juno bij regie op de woningbouwopgave
- Van plannen naar projecten: zo helpt de Woningbouwimpuls gemeenten vooruit
- Koppelen met Juno: de API maakt het mogelijk
- De Realisatiestimulans komt eraan: waarom goede monitoring belangrijker is dan ooit
- Hoe de Basisset 2.0 helpt bij gegevensuitwisseling over de woningbouwopgave met Juno
- De gemeenteraad informeren over de woningbouwopgave met Juno
- Juno: informatieknooppunt voor publiek-private samenwerking (PPM)
Nieuws
- Webinar 24 maart: Grip op woningbouw in 2026
- Shintō Labs aanwezig op de Dag van de Volkshuisvesting
- Juno OWK volledig bijgewerkt voor WCAG 2.2
- Gemeente Vught live met openbare woningbouwkaart van Juno
- Shintō Labs partner in onderzoek naar digitale versnelling van energierenovaties
- Metropoolregio Eindhoven kiest voor publieke versie van Juno
- Provincie en alle gemeenten in Drenthe omarmen publieke versie van Juno
- Publieke Juno Gemeente Eindhoven live
- Gemeente Kampen gaat voor datagedreven aanpak woningbouwopgave
- Provincie Limburg kiest voor Juno
- Provincie Groningen kiest voor Juno





















