Hoe je als gemeente kan vernieuwen met data en technologie in 5½ tips
Naast haar werk voor Shintō Labs, verdedigt Mignon Wuestman op 26 juni a.s. haar proefschrift over de evolutie van innovaties voor de Universiteit Utrecht. Zij deed vier jaar lang onderzoek naar de ‘stambomen’ van (wetenschappelijke) innovaties, en werkte op het raakvlak van onder andere complexiteitstheorie, economische geografie en sociologie. In deze blog deelt ze een aantal inzichten uit haar promotieonderzoek en gerelateerde onderzoeken, specifiek binnen de context van de lokale overheid.
Innovatie is een belangrijke drijvende kracht achter bedrijven, overheden en andere maatschappelijke spelers. Het helpt namelijk om maatschappelijke en technische problemen op te lossen, productiekosten te verlagen, je te onderscheiden van anderen, of nieuwe markten aan te boren. Daarnaast speelt innovatie natuurlijk een enorme rol in de wetenschap en in de kunst.
Het bedenken van nieuwe ideeën, het selecteren van goede ideeën, en het daadwerkelijk tot uitvoering brengen van die ideeën is echter niet eenvoudig. Dat komt doordat innovatie per definitie onzekerheid met zich meebrengt. De (maatschappelijke) problemen die we willen oplossen zijn over het algemeen namelijk zo complex dat het onmogelijk is om ze volledig te overzien. Daarnaast kunnen we niet in de toekomst kijken om goed te beoordelen wat het effect van een bepaalde innovatie zal zijn. Het gevolg daarvan is dat het vaak niet mogelijk is om volledig rationele beslissingen te maken, zoals vaak door economen wordt verondersteld. Om ondanks deze onzekerheid toch te kunnen innoveren is dus een belangrijke vraag: hoe kunnen overheden het beste omgaan met de onzekerheid van innovatie?
Innovatie is staan op de schouders van reuzen
In het kort zijn innovaties op de markt gebrachte inventies. Het kan daarbij gaan om producten die je vastlegt in patenten en in een winkel verkoopt, maar ook om wetenschappelijke ontdekkingen die opgeschreven en gepubliceerd worden, of bijvoorbeeld nieuw beleid dat ingevoerd wordt.
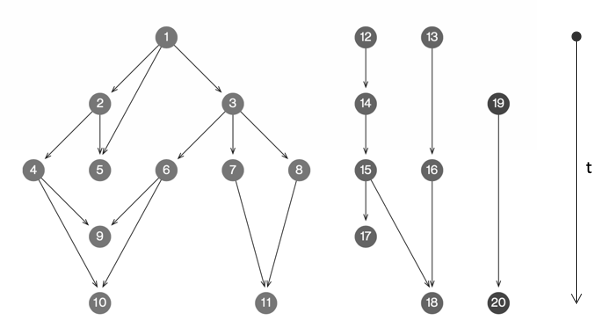
Figuur 1: stamboom van innovaties
Het ontstaan van innovatie wordt vaak vergeleken met de evolutie van planten en dieren. Net als in de biologie, zijn termen als ‘mutatie’, ‘fitness’, en ‘selectieomgeving’ ook relevant bij innovaties. Net als in de biologie, is het ook bij innovaties zo dat je verschillende generaties kan onderscheiden, en wordt er informatie doorgegeven van generatie op generatie. In de biologie heb je het dan over DNA, in de innovatietheorie gaat het bijvoorbeeld om producteigenschappen. Waar je in de biologie dus met stambomen, of ‘genealogieën’ kan werken om deze ontwikkeling te visualiseren, kan dat met innovaties dus ook (figuur 1). In het kort geldt voor dat soort netwerken:
- Ieder bolletje stelt een idee (een innovatie) voor. Zo’n idee kan zijn vastgelegd in een patent, een wetenschappelijk artikel, een beleidsstuk of het brein van een slimme uitvinder of het collectieve brein van een team
- Ieder lijntje staat voor het erven van bepaalde eigenschappen van idee naar idee
- Ideeën kunnen eigenschappen erven van meerdere bestaande ideeën. Dat noemen we ‘recombinatie’.
- Door dit proces ontstaan er paden die divergeren en convergeren, en die daarmee iets zeggen over de evolutie van ideeën.
Precies dit soort netwerken vinden we terug onder wetenschappelijke artikelen en patenten (figuur 2), teams van jazzmuzikanten (figuur 3), en in het geval van mijn thesis, wiskundigen (figuur 4). Naast netwerken van patenten, papers, teams of individuen zijn dit dus ook netwerken van innovaties.
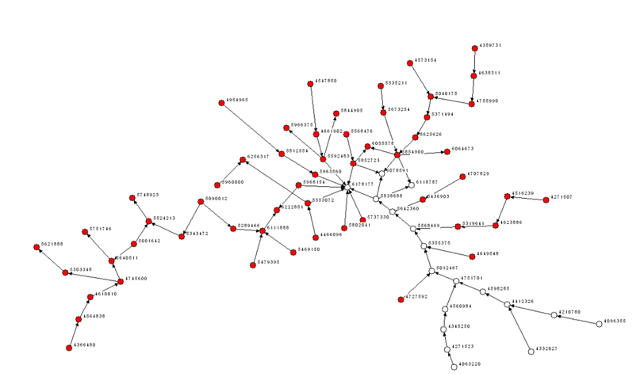
Figuur 2: Citatienetwerk van Ethernet-patenten 1977-2002 (Fontana et al., 2009)
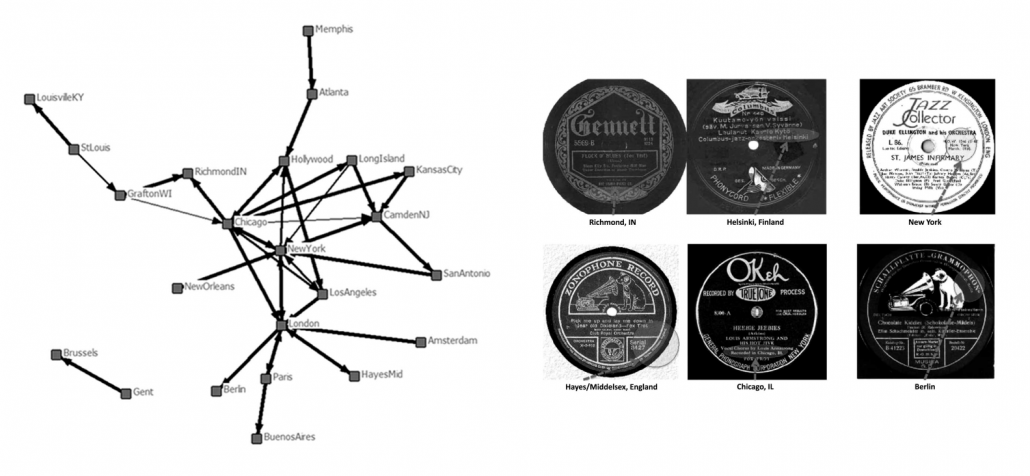
Figuur 3: Netwerk van steden verbonden door jazzmuzikanten-mobiliteit (Phillips et al., 2011)
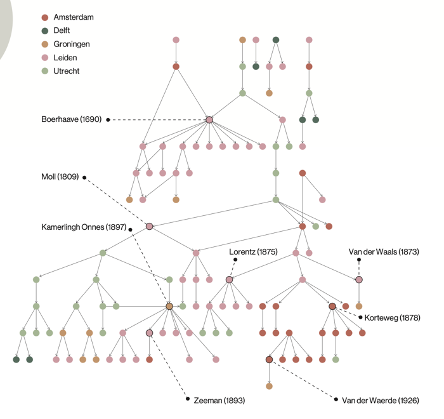
Figuur 4: Mentorschapsgenealogie van Nederlandse wiskundigen (Wuestman et al., 2020)
Er zijn veel voorbeelden te geven van overheidsprocessen die de recombinatorische aard van innovatie illustreren. Kruisbestuivingen tussen verschillende lokale overheden, afdelingen of teams zijn een goed voorbeeld. Individuele werknemers nemen ook ideeën mee uit eerdere projecten of banen.
Nu je weet dat innovaties voortkomen uit het recombineren van eerdere innovaties, is het niet moeilijk om je voor te stellen hoeveel innovaties er mogelijk zijn. In theorie kan ieder ‘bolletje’ gecombineerd worden met ieder ander bolletje. We kunnen er echter niet vanuit gaan dat ieder van die combinaties ook een goed idee oplevert (of, in evolutionaire termen: een hoge ‘fitness’ heeft). Sterker nog, dikke kans dat de overgrote meerderheid geen goed idee is. Als innovator ben je dus op zoek naar een speld in een hooiberg. Hoe voorkom je dat je je blind staart op het hooi, en zo snel mogelijk die speld vindt?
1. Bepaal je doel
Er zijn verschillende types innovaties. Grofweg onderscheiden we er twee: incrementele en radicale innovaties.
Incrementele innovaties zijn kleine veranderingen die ons idee over ‘hoe de wereld in elkaar steekt’ in stand houden. Het zijn verbeteringen aan bestaande eigenschappen die bijvoorbeeld de gebruiksvriendelijkheid vergroten of het productieproces versnellen. Als we incrementele innovaties bekijken vanuit het evolutionaire perspectief dat ik hierboven heb uitgelegd, kun je incrementele innovaties vaak zien als recombinaties van ideeën die op elkaar lijken. Combineer bijvoorbeeld de goede eigenschappen van bolletje #9 met de goede eigenschappen van bolletje #10 met elkaar. In lokale overheden komen natuurlijk veel innovaties voor, waaronder veel incrementele innovaties. Zo kan een gemeente bijvoorbeeld de aanpak van een andere gemeente overnemen, maar deze aanpassen naar de lokale omstandigheden.
Radicale innovaties zijn grote veranderingen die wel onze aannames over de wereld op het spel zetten. Radicale innovaties leiden tot nieuwe paradigma’s. Vanuit evolutionair perspectief kan je zeggen dat radicale innovaties tot belangrijke nieuwe vertakkingen in een netwerk van ideeën leiden. Vaak zijn radicale innovaties tot stand gekomen door recombinaties van heel diverse ideeën: bolletjes die in het netwerk heel ver uit elkaar liggen, zoals bolletjes #10 en #16. Natuurlijk komen ook radicale innovaties voor in de overheid. Dit gebeurt bijvoorbeeld wanneer een overheidsorganisatie methoden uit de start-up wereld gebruikt om toe te passen op overheidsproblematiek.
Incrementele innovaties komen dus vaak tot stand door recombinaties van ideeën die op elkaar lijken, terwijl radicale innovaties recombinaties zijn van ideeën die niet op elkaar lijken. Dit gegeven kan je gebruiken wanneer je wil innoveren. Het kan nuttig zijn om jezelf af te vragen of je uit bent op een kleine verbetering of op een rigoureuze doorbraak. Zoals ik eerder zei, kan je je het netwerk van ideeën namelijk ook voorstellen als een netwerk van mensen. Als je het zo bekijkt, zou je kunnen concluderen dat incrementele innovaties vaak bedacht worden door teams van mensen die op elkaar lijken, zoals experts op het product dat verbeterd moet worden, terwijl radicale innovaties vaak bedacht worden door diverse teams die in staat zijn inzichten uit verschillende werelden te combineren.
Tip 1: radicale innovaties vragen om diversere ‘inputs’ dan incrementele innovaties.
Een consequentie van het combineren van ideeën die ver uit elkaar liggen is niet alleen dat ze een grotere kans hebben om tot een doorbraak te leiden. Ideeën die zo ver uit elkaar liggen zijn namelijk waarschijnlijk veel moeilijker te combineren dan ideeën die op elkaar lijken. Dat kan komen doordat niemand eerder zoiets geprobeerd heeft, of omdat de ideeën zo verschillend zijn dat ze nauwelijks compatibel zijn. Het is daarom aannemelijk dat incrementele innovaties tot een relatief kleine opbrengst leiden, maar ook minder risicovol zijn, terwijl radicale innovaties een enorme opbrengst kunnen leveren, maar ook een grotere kans hebben om op niks uit te draaien. Ook dat is iets om rekening mee te houden wanneer je wil innoveren!
Tip 2: diversiteit aan inputs is ‘high risk, high gain, dus kies waar je voor wil gaan.
| Survival of the fittest bij start-ups en spin-offs Neem bijvoorbeeld het concept van ‘spin-offs’. Spin-offs zijn kleine, nieuwe bedrijven die ontstaan vanuit grotere, gevestigde bedrijven. Vaak is het zo dat een werknemer bij een gevestigd bedrijf vertrekt omdat zij een idee heeft dat niet past binnen het gevestigde bedrijf, en besluit haar eigen bedrijf te beginnen. De kans is groot dat zij daarbij toch een aantal aspecten van het gevestigde bedrijf zal meenemen, zoals de kennis die zij daar heeft opgedaan. Deze kennis ‘erft’ het nieuwe bedrijf dus van het oude bedrijf. Niet alle spin-offs zullen lang blijven bestaan: alleen die spin-offs die het lukt om zich zo te ontwikkelen dat zij goed aansluiten bij de markt en relevante productieketens zal het lukken om succesvol te zijn. In andere woorden: die bedrijven die zich het best weten aan te passen aan hun selectieomgeving. U ziet het al aankomen: survival of the fittest. |
2. Fail fast
Om snel tot dat ene goede idee tussen de 99 slechte ideeën te komen is het natuurlijk belangrijk om zo min mogelijk tijd, geld en frustratie te besteden aan ideeën die uiteindelijk niet blijken te werken. Dat is natuurlijk behoorlijk intuïtief, maar er is ook een innovatietheoretische reden om niet te veel te investeren in ideeën die zichzelf nog niet bewezen hebben. Dat heeft te maken met ‘padafhankelijkheid’.
Padafhankelijkheid betekent dat wanneer we eenmaal een bepaalde route zijn ingeslagen in het netwerk van innovaties, het heel lastig is om nog van die route af te wijken. Daar zijn een aantal redenen voor. Ten eerste is het door de recombinatorische aard van innovaties zo dat onze opties op dit moment worden bepaald door onze keuzes uit het verleden. Je kan immers alleen combinaties maken van ideeën die er al zijn. Als je veel investeert in een bepaald pad, vorm je daarmee dus een belangrijk deel van je bibliotheek aan ideeën. Ten tweede raken we vaak ‘locked-in’ in ideeën waar we als maatschappij veel in geïnvesteerd hebben. Ter illustratie: in tegenstelling tot u misschien denkt is ons QWERTY-toetsenbord helemaal niet ontworpen om zo snel mogelijk te kunnen typen. Het QWERTY toetsenbord komt uit de tijd van de typemachines, en is zo ontworpen dat lettercombinaties die vaak voorkomen ver uit elkaar geplaatst zijn, zodat de hamertjes van de typemachine niet in de knoop raken. Het toetsenbord is voor ons dus suboptimaal en helpt ons niet om snel te typen. Het lukt ons echter niet om over te stappen naar een sneller of ergonomischer toetsenbord, want probeer maar eens opnieuw te leren typen. Iets soortgelijks geldt ook voor de overstap van benzine- en dieselauto’s naar elektrische auto’s, waarvoor er nog niet zo’n gedegen infrastructuur bestaat als voor benzineauto’s. Nationale en lokale overheden hebben bij uitstek te maken met dit soort ‘interdependencies’, omdat zij verantwoordelijk zijn voor het beheer van hele systemen en niet, zoals vaak in de bedrijfswereld voorkomt, van individuele producten.
Het gevolg van padafhankelijkheid is dat het belangrijk is om veel te leren over verschillende alternatieve oplossingen voor een probleem, zodat je kan voorkomen dat je je committeert aan een suboptimale oplossing. Lock-ins kan je niet helemaal voorkomen omdat je niet kan weten of een optimale oplossing op dit moment in de toekomst nog steeds de beste oplossing is, maar het helpt zeker om op de hoogte te blijven van nieuwe ontwikkelingen en gekozen oplossingen altijd te blijven valideren. Investeer dus niet te veel in die 99 slechte ideeën. Zet in op leren, en wees bereid om van richting te veranderen als dat nodig is.
Tip 3: voorkom dat je vastzit in een suboptimale oplossing door veel te experimenteren
Tip 4: begin vroeg met valideren, en blijf valideren.
3. Denk modulair
Maatschappelijke en technische problemen zijn vaak niet alleen complex in de zin van ‘ingewikkeld’, maar ook in de zin van ‘complexe systemen’. Complexe systemen zijn systemen die bestaan uit heel veel kleine, relatief eenvoudige, onderdeeltjes. Door de interactie tussen die onderdeeltjes ontstaan patronen die bijna niet te verklaren zijn. Denk bijvoorbeeld aan het dansen van een zwerm spreeuwen, auto’s die files vormen, onze hersenen en de zenuwcellen daarbinnen, of het ecosysteem in een bos. Het ingewikkelde daaraan is dat je bij een complex systeem nooit helemaal kan overzien wat de gevolgen van een interventie zijn. Als je te veel zwijnen in een bos uit zou zetten, zou er door de interactie van die zwijnen met andere onderdelen van het systeem zomaar een onvoorziene insectenplaag kunnen ontstaan. Bij innovatie in onze maatschappij werkt het net zo: wanneer je één onderdeel van de maatschappij verandert, zou dat kunnen betekenen dat een heel ander onderdeel niet meer werkt of anders werkt.
| Stambomen van gereedschappen Over de hele wereld worden de meeste antropologische musea ingericht per bevolkingsgroep of werelddeel. Het Pitt Rivers Museum in Oxford, waar ik vaak kwam toen ik voor mijn promotieonderzoek een paar maanden te gast was aan de universiteit, besloot het anders aan te pakken. Meneer Rivers hield bij zijn (enigszins omstreden) collectie gebruiksvoorwerpen geen geografische indeling maar een evolutionaire indeling aan. Hij verzamelde bijvoorbeeld alle knuppels die hij had, en vormde hiermee een soort stamboom. In het plaatje hieronder is prachtig te zien hoe het ontwerp van de knuppel varieerde van plek tot plek, en door de tijd heen steeds verder divergeerde. Dat is op zich niet gek, want knuppels zijn een cultureel product dat door mensen wordt gemaakt en wordt aangepast aan hun lokale omgeving. Dat is toch fascinerend? |
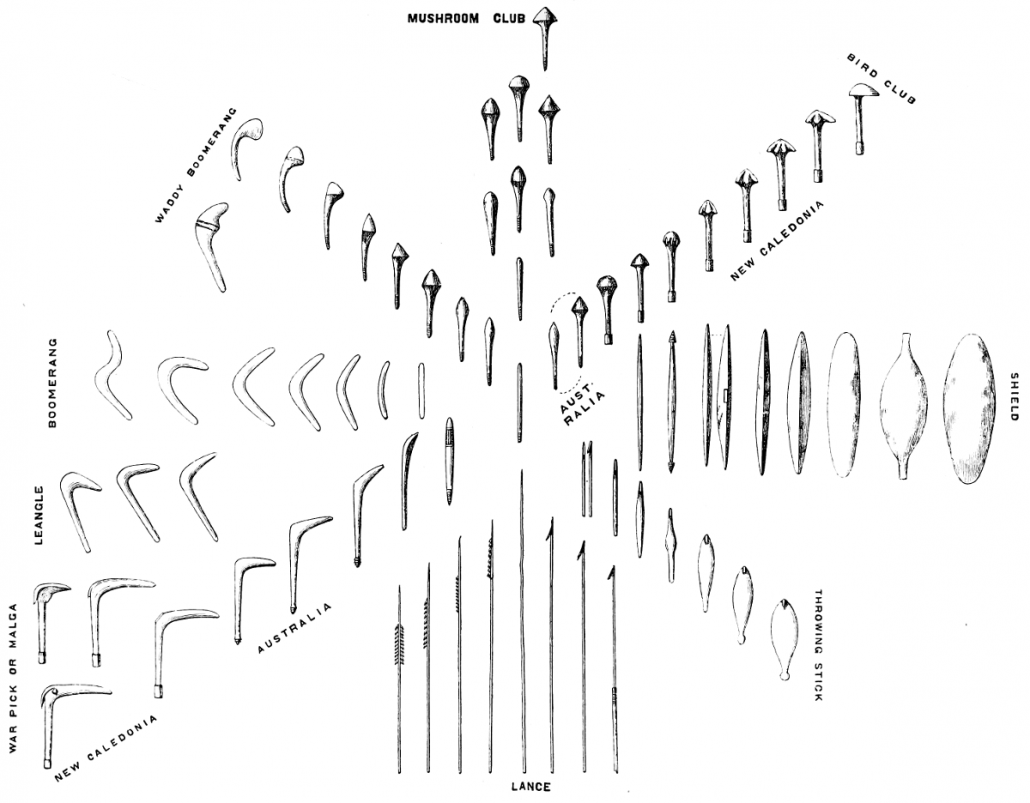
Figuur 5: Evolutionaire indeling knuppels (Pitt Rivers Museum Oxford)
In de wereld van de criminaliteitsbestrijding is er bijvoorbeeld sprake van het ‘waterbedeffect’: wanneer er druk wordt uitgeoefend op een vorm van criminaliteit op een bepaalde plek, zoals witwassen in een specifieke gemeente, kan dat als gewenst gevolg hebben dat die vorm van criminaliteit afneemt. Een onvoorzien bij-effect kan echter zijn dat er een toename ontstaat van criminaliteit op een andere plek, of van andere soorten criminaliteit, omdat de criminele activiteit zich verplaatst.
Soms kan dit soort complexiteit verholpen worden door het probleem op te delen in verschillende geïsoleerde modules. In dat geval spelen de complexe afhankelijkheden alleen binnen een module, en niet tussen modules onderling. Dan kunnen modules afzonderlijk geoptimaliseerd worden, en dat is veel makkelijker dan het optimaliseren van het hele systeem. In onze complexe samenleving is dat helaas makkelijker gezegd dan gedaan. In zo’n geval geldt: wees je bewust van de complexiteit van het probleem dat je probeert op te lossen. Staar je niet blind op een specifiek voorval, maar bestudeer de context waarin dit voorval plaatsvindt en verken welke mogelijke bij-effecten kunnen optreden bij een interventie.
Tip 5: denk en experimenteer op onderdelen, en niet op het geheel.
Tip 5: als Tip 5 niet lukt, wees je dan tenminste bewust van complexiteit.
Vodcast
Zie ook de vodcast van Mignon over dit onderwerp:
Relevante links
- Vodcast: Innovatietheorie voor de datagedreven overheid
- Shintō Design Sprint
- Whitepaper ‘Van maatschappelijke opgave naar datagdreven toepassing’
- 32 Design Sprint Tips na 2 jaar ervaring in de praktijk
- Waarom de Design Sprint dé oplossing is voor datagestuurd werken
- Van datagestuurd naar waardegestuurd werken
- Vijf redenen waarom je datagedreven werken als gemeente samen moet doen
- Training Design Sprinten voor Sprintmasters
- Training Design Sprinten voor Data Scientists
Credits