Eind 2020 hebben we twee Design Sprints uitgevoerd om een uitbreiding van onze ondermijningsapplicatie te ontwikkelen. Deze twee sprints draaiden om ‘misbruik van vastgoed’ en waren uitgevoerd bij een grote en een middelgrote gemeente. In slechts enkele dagen ontwikkelden wij daar een prototype voor een datagdreven aanpak van dit probleem. Deze blog geeft een verslag van deze Design Sprints en de stappen die wij doorlopen hebben om tot dat prototype te komen. We laten zien hoe we de uitdaging, het probleem, vertaald hebben in een prototype met indicatoren, kaarten, filters en netwerkanalyses. En waarin we verschillende manieren verkennen om de privacy van burgers te waarborgen.
De aanpak van ondermijnende criminaliteit binnen een gemeente wordt vaak geprioriteerd in lijn met de de focus zoals die ook vaak door de RIEC’s (Regionale Inlichtingen en Expertise Centra) wordt aangebracht. Deze terugkerende thema’s zijn:
Misbruik en fraude binnen de vastgoedsector (en het witwassen dat daar regelmatig mee gepaard gaat) is daarmee één van de belangrijke pijlers in de bestrijding van ondermijnende criminaliteit. In de vele gesprekken die wij met verschillende lokale en regionale overheidsorganisaties hebben gehad is de aanpak misbruik vastgoed ook een van de meest genoemde vraagstukken.
Bij de gemeentes in kwestie speelden bovendien specifieke vraagstukken in relatie tot de ‘Woondeals’ (van het ministerie van BZK) en een organisatieverandering gericht op datagedreven werken en gebiedsgericht werken (domein-overstijgende samenwerking). De Design Sprints die we hebben uitgevoerd moesten ook deze context meenemen.
In de voorgesprekken met de betrokken gemeentes werd benoemd dat er verhoudingsgewijs veel ABC-constructies toegepast worden – een arbitraire eerste plaats waar iets aan gedaan moest worden. (Een ABC-constructie of ABC-akte is een vastgoedtransactie waarbij een gebouw of woning binnen zeer korte tijd twee keer verkocht wordt, van A naar B en van B naar C. Het gebouw gaat daarmee feitelijk van A naar C. Een ABC-transactie is gevoelig voor fraude zoals hypotheekfraude, belastingontduiking en witwassen.)
Wij starten een Design Sprint altijd met een Big Challenge – het buikpijndossier. Dat is een van de belangrijkste succesfactoren van een Design Sprint. De Big Challenge voor deze Design Sprint gericht op het misbruik van vastgoed is de volgende:
‘Kunnen we zicht krijgen op het misbruik van vastgoed in onze wijken zodat de gemeente en haar partners interventies kunnen plannen voor zichtbaar resultaat’
Deze challenge is gericht op het verkrijgen van zicht op en inzicht in vastgoed misbruik als verschijningsvorm van ondermijnende criminaliteit. Een terugkerende vraag daarbij is wanneer gebruik over gaat in misbruik en hoe dat te constateren is. Een andere factor is het inzichtelijk kunnen krijgen van de dynamiek binnen het speelveld van panden, personen en ondernemingen rondom het thema misbruik van vastgoed. Tenslotte bleek tijdens de sprints er dat er binnen de gemeente verschillende rollen zijn die hun eigen taken en verantwoordelijkheden hebben en die niet altijd dezelfde belangen hebben. Zo kan het innen van leges voor het afhandelen van vergunningsaanvragen mogelijk conflicterend zijn met het doorvragen bij een mogelijk verdachte aanvraag en de signaleringsfunctie die daarbij hoort.
De lange termijn doelstelling is als volgt gedefinieerd: “Een goede datahuishouding rondom vastgoedmisbruik, wat zorgt voor een duurzaam informatiebeeld dat integraal gedeeld wordt en domeinen overstijgt, ten behoeve van gedeelde verantwoordelijkheid en urgentiebesef.”
Het achterliggende idee was dat er verschillende domeinen als ‘silo’s’ opereren, geen gedeeld beeld hebben, of de urgentie missen om een gezamenlijke aanpak te definiëren. Vastgoedmisbruik raakt namelijk niet alleen het veiligheidsdomein, maar ook het sociaal domein, het ruimtelijk domein, en overstijgende thema’s zoals de leefbaarheid in wijken en buurten.
Een vast onderdeel van de Design Sprint is het bepalen van de waardepropositie (Value Proposition). Het idee van de waardepropositie is om te bepalen waar de pijn precies zit, uitgedrukt in drie onderdelen: jobs, pains en gains. Hieronder een indruk van de jobs, pains en gains die tijdens de sprints ter sprake zijn gekomen. Dit is natuurlijk geen uitputtende lijst!
1. Jobs: welke taken moeten er gedaan worden?
Een relevante job rondom het thema vastgoedmisbruik is natuurlijk het inzichtelijk krijgen van dit misbruik, maar ook het zorgen voor bewustwording, draagvlak en urgentiebesef bij de verschillende betrokken partijen, en het kunnen bieden van handelingsperspectief. Dit alles mag niet ten koste gaan van de privacy van al dan niet betrokken personen; het waarborgen daarvan is een andere relevante taak.
2. Pains: wat zijn de grootste pijnpunten die we moeten weghalen?
Er zijn diverse factoren die een drempel opwerpen voor het kunnen uitvoeren van die taken. De zojuist besproken silo’s zijn hier een belangrijk voorbeeld van. Een consequentie van die silo’s is dat veel kennis en informatie er wel degelijk is, maar verspreid is tussen verschillende partijen die ieder hun eigen gebruiken en definities hanteren. Dat is natuurlijk begrijpelijk, maar maakt het lastiger een silo-overstijgende aanpak van vastgoedmisbruik te formuleren
3. Gains: wat zou helpen bij het uitvoeren van taken? Wat is essentieel, en wat is nice to have?
Het in kaart brengen van stakeholders en betrokkenen, en hun rollen, is een belangrijke stap richting het inzichtelijk maken van vastgoedmisbruik en het bieden van relevant handelingsperspectief voor de betrokken partijen. Ditzelfde geldt voor het toepassen van objectieve indicatoren die daadwerkelijk indicatief zijn voor vastgoedmisbruik. Een genoemde wens is niet alleen reactief op te treden bij vastgoedmisbruik, maar de gewonnen inzichten rondom dit thema ook proactief te kunnen inzetten, bijvoorbeeld door als gemeente zelf actief te zijn in vastgoed.
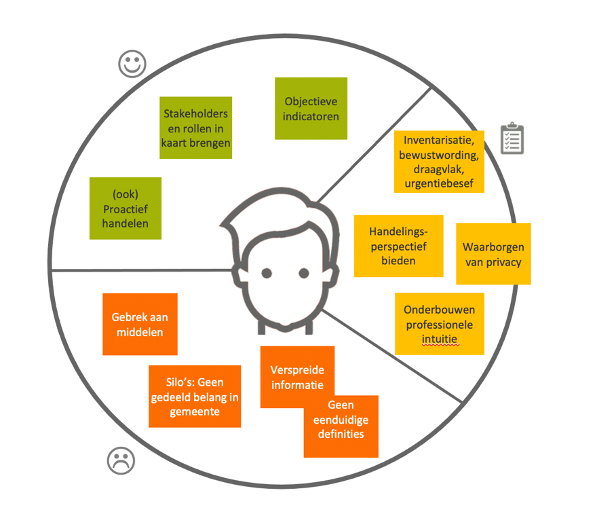
Afbeelding: Canvas waardepropositie rondom het thema vastgoedfraude
Tijdens een Design Sprint ontwerpen we een instrument dat kan helpen bij een of meerdere jobs, en waar mogelijk pains verlicht en gains creëert. Bij het ontwikkelen van dit prototype hebben wij rekening gehouden met twee scenario’s. Beide scenario’s zijn tijdens de Design Sprint vastgelegd in een storyboard (een verhalende beschrijving van het proces) dat het verloop van ieder van deze scenario’s omschrijft.
Scenario 1: De casemanager
In dit scenario nemen we een persoon in de rol van casemanager als uitgangspunt. We starten dit scenario met een voorval op een specifiek adres. Dit kan van alles zijn, zolang er aanleiding is om te vermoeden dat er sprake is van vastgoedmisbruik. Dit voorval vormt de start van het onderzoek, waarbij de casemanager wil weten wat er bekend is over het betrokken adres, zoals wie er wonen of welke bedrijven er gevestigd zijn. De casemanager raadpleegt het instrument om dit onderzoeken. Hij/zij gebruikt het instrument om te onderzoeken wat er bekend is over het adres, in de vorm van een kaart, een casusoverzicht, en een netwerk. Deze gegevens kan hij/zij exporteren en meenemen naar een briefing over het betreffende voorval, waarna een actieplan geformuleerd kan worden. Na het uitvoeren van dit actieplan is er mogelijk nieuwe informatie over het betreffende adres. De casemanager zal dan opnieuw het instrument openen, en het instrument aanvullen met deze nieuwe inzichten.
Scenario 2: De analist
Voor dit scenario kijken we door de ogen van een analist. Het startschot van dit scenario is voor de analist een reden om trends en patronen in kaart te brengen, bijvoorbeeld naar aanleiding van een vraag van een verslaggever. De analist raadpleegt het instrument niet zozeer om gegevens over een specifiek adres in te zien, maar om patronen en ontwikkelingen te documenteren. Waar de casemanager kijkt naar het specifieke adres en diens relaties in het netwerk, zal de analist geïnteresseerd zijn in het netwerk in zijn geheel. Ze zal vervolgens haar conclusies vastleggen en presenteren.
Waar de casemanager en de analist in principe dus hetzelfde instrument raadplegen, doen zij dit met twee verschillende vragen en doorlopen zij daarmee twee verschillende routes door het instrument. Hun verschillen in rol en bevoegdheden maken dat ook hun rechten binnen het instrument verschillend zijn. Zo zal het voor een analist vaak niet nodig zijn om toegang tot persoonsgegevens te hebben, terwijl dit voor de casemanager wel nodig kan zijn. Meer hierover later in deze blog!

Afbeelding: ontwikkeling van het storyboard vanuit het perspectief van de casemanager
Voor het onderzoeken van datagedreven aanpak voor het misbruik van vastgoed hebben we verschillende indicatoren onderzocht. Met hulp van publicaties van organisaties die onderzoek doen naar ondermijning, en de ervaring van de experts die deelnamen aan de sprint, hebben we een lijst met indicatoren benoemd. Deze indicatoren zijn op te delen in drie categorieën.
Ten eerste zijn daar de indicatoren die iets zeggen over speculatie met vastgoed, zoals opvallende transacties. Ten tweede zijn er indicatoren die iets zeggen over de exploitatie van vastgoed, zoals overbewoning en de gevestigde ondernemingen. Een derde groep bestaat uit indicatoren die ons kunnen helpen bij het vaststellen van het speelveld, zoals familienetwerken en diverse tussenpersonen zoals makelaars en hypotheekverstrekkers. We noemen hier een deelverzameling van de meest waardevol geachte indicatoren:
Speculatie indicatoren
Exploitatie indicatoren
Speelveld indicatoren
Er zijn natuurlijk veel databronnen die iets kunnen zeggen over het gebruik en misbruik van vastgoed. Eigendom van panden, en transacties van panden, worden bijvoorbeeld uitgebreid vastgelegd door het Kadaster, en de ondernemingen die erin gevestigd zijn door de Kamer van Koophandel. Daarnaast zijn er verschillende gemeente-specifieke databronnen die kunnen bijdragen aan een beeld van vastgoedmisbruik. Om inzicht te krijgen in mogelijk vastgoedmisbruik zijn deze registraties echter niet voldoende: ook de verschillende experts in het veld bezitten waardevolle informatie. Om een compleet beeld te krijgen van speculatie en exploitatie van vastgoed in een buurt of wijk is het belangrijk om gegevens uit registraties en kennis van betrokken professionals met elkaar te combineren. Zo is het in dit prototype mogelijk om zelf opmerkingen, waarschuwingen, of relevante connecties toe te voegen, en zo een dossier op te bouwen.
In een Design Sprint werken we soms met ‘nepdata’, omdat het niet altijd mogelijk is om (snel) toegang te krijgen tot de echte data, bijvoorbeeld omdat het persoonsgegevens betreft (zie onderdeel ‘privacy’ hieronder) of omdat het verzamelen van databronnen nou eenmaal een tijdrovend proces is. Voor het succes van de Design Sprint is dat meestal geen probleem. Het gaat er bij een sprint immers om het verkennen van een route, en het kunnen beoordelen of het geprototypte idee in potentie waardevol is. Bij iedere sprint waar we gebruik maken van nepdata staan we natuurlijk wel stil bij de aannames die we hiervoor moeten maken, en in hoeverre het succes van het prototype afhankelijk is van data die nog niet beschikbaar is.

Afbeelding: het potentieel nut en de haalbaarheid van verschillende datasets
Vanzelfsprekend zijn niet alle relevante bronnen die in het instrument opgenomen zouden kunnen worden zomaar toegankelijk. Dit is doorgaans in de eerste plaats om de privacy van betrokken personen te waarborgen. Ook wanneer een dataset al opgenomen zou zijn in een instrument, is het niet vanzelfsprekend zo dat iedere gebruiker hier toegang toe mag hebben. Bepalingen over toegang tot de data in het prototype is afhankelijk van het door de gemeentes gehanteerde privacyprotocol.
De Rijksoverheid ontwikkelde een handleiding voor een model van zo’n protocol voor binnengemeentelijke gegevensuitwisseling ten behoeve van de bestrijding van ondermijning. Dit model maakt gebruik van een aantal wegingen en checks om te bepalen wie er in welke situatie toegang heeft tot gegevens. Een schematische weergave hiervan staat in de afbeelding hieronder. Wanneer een signaal een functionaris van de gemeente bereikt, zoals de hierboven genoemde casemanager, moeten er bijvoorbeeld een aantal dingen gecheckt worden. Kan er hier sprake zijn van ondermijning? Is het onze gemeentelijke taak om iets met dit signaal te doen? Gaat het hier wel over ons grondgebied of een inwoner van onze gemeente? Hoe zwaar is dit signaal?
Om deze vragen te kunnen beantwoorden mag een casemanager informatie gebruiken uit openbare bronnen, zoals bijvoorbeeld de Kamer van Koophandel, het Kadaster, de BRP en de BAG. Zoals hierboven beschreven kan de casemanager daar het prototype voor gebruiken. Aan de hand van die beantwoorde vragen bepaalt een privacy officer welke bronnen de casemanager verder mag raadplegen. Interessant hierbij is de ‘hit/no hit-vraag’: is het voor de casemanager voldoende om te weten of een persoon bijvoorbeeld voorkomt in een dataset (of er een hit is), of is het noodzakelijk dat de casemanager daadwerkelijk ziet wat er in die dataset staat?
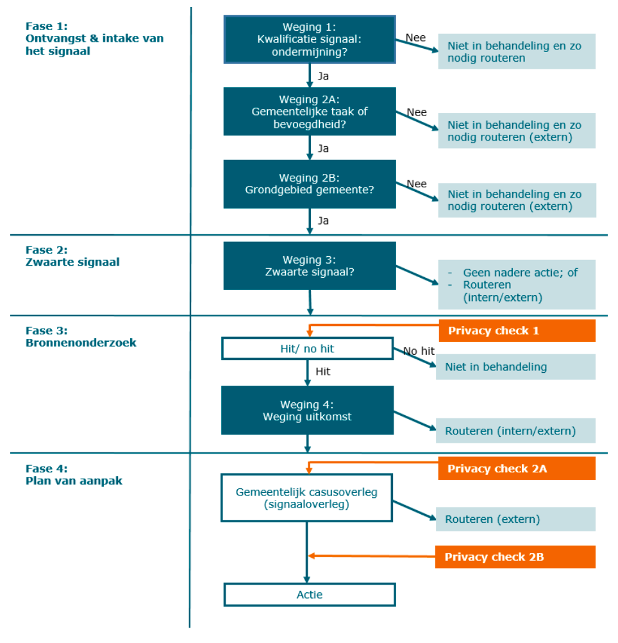
Afbeelding: het privacy protocol
Zoals al eerder genoemd is het dus niet zo dat iemand die het geprototypte instrument raadpleegt vanzelfsprekend toegang zou mogen hebben tot alle beschikbare informatie. Het zorgvuldig vastleggen van de verschillende rechten en het faciliteren van de diverse beslissingen die bij het doorlopen van het privacy protocol genomen worden heeft natuurlijk consequenties voor de inrichting van het instrument. Het op deze manier ontwerpen van een instrument, waarbij gedurende het hele ontwerp rekening wordt gehouden met zo’n privacyprotocol, wordt ook wel ‘privacy by design’ genoemd. We hebben tijdens de Design Sprint uitgebreid stilgestaan bij het verkennen van de technische mogelijkheden om privacy zo goed mogelijk te waarborgen in het instrument.
Een andere manier waarop we privacy zo goed mogelijk proberen te waarborgen is het anonimiseren (of pseudonimiseren) van alle gebruikte data. Zo zijn individuen, panden en ondernemingen allemaal versleuteld, en zijn er slechts bepaalde mensen die toegang hebben tot die sleutel. Het grote voordeel daarvan is dat een gebruiker niet alleen onderzoek kan doen naar trends en patronen, maar ook naar individuele cases, zonder dat hierbij persoonsgegevens gedeeld worden met de gebruiker. Afhankelijk van of de versleuteling plaatsvindt bij de opdrachtgever of bij ons, hebben wij (als Shintō Labs) op die manier ook geen toegang tot persoonsgegevens nodig om data te kunnen verwerken! In zo’n geval kunnen wij onze opdrachtgevers helpen bij het ontwikkelen van een versleutelprotocol.
Dit prototype is ontwikkeld vanuit ons concept van lenzen. Hierover kunt u meer lezen in ons whitepaper ‘Een datagedreven aanpak van ondermijnende criminaliteit’. In een lens komen een aantal standaardonderdelen terug: de gebiedskaart en/of locatiekaart, en een detailpagina met daarin casusinformatie en het casusnetwerk. Dit prototype heeft een extra onderdeel: het melden van een signaal.
Signaal melden
Voor een casemanager (scenario 1) is dit het voornaamste beginpunt. De casemanager kan hier informatie over een signaal kwijt, zoals de aard en zwaarte van het signaal, eventuele betrokkenen, en informatie over de betrokken locatie. De informatie die de casemanager hier invult sluit aan bij de verschillende fases uit het privacy protocol en kan bijdragen aan het doorlopen van de verschillende privacy checks. Zo wordt stapsgewijs beoordeeld of het signaal betrekking heeft op ondermijning. Uiteindelijk zou dit proces moeten helpen bij het beoordelen tot welke gegevens de casemanager toegang zou moeten hebben, en wat mogelijke vervolgstappen zijn.
Kaart
In de buurtkaart wordt de betreffende gemeente weergegeven met daarin de verschillende buurten. Op deze kaart worden alle data op pandniveau of op buurtniveau ontsloten; data over specifieke panden kan bijvoorbeeld worden geaggregeerd tot de buurt waartoe het pand behoort. Zo kan een gebruiker een beeld krijgen van de situatie in een buurt, zonder dat dit herleidbaar is tot individuele personen, panden of ondernemingen. De gebruiker kan gebruik maken van een aantal filters die overeenkomen met indicatoren van vastgoedmisbruik.
Informatie over buurten wordt niet alleen weergegeven op de kaart, maar kan ook op een rijtje gezet worden in de buurtvergelijker. Hier kan een gebruiker twee buurten naast elkaar zetten om kengetallen te vergelijken, of te beoordelen of de twee buurten anders presteren als het gaat om een specifieke indicator. Hierbij helpt het ook om bijvoorbeeld een indicator af te zetten tegen de tijd, om te beoordelen of een buurt zich in dit opzicht ontwikkeld heeft.
Details
Op de detailpagina wordt alle relevante informatie over een geselecteerd persoon, pand of onderneming verzameld. Alle personen, panden en ondernemingen zijn hier versleuteld. Welke data worden weergegeven kan daarbij afhankelijk zijn van het privacy protocol en de rechten van de gebruiker. Een interessante functionaliteit op de detailpagina is het context diagram. Hierin worden de relaties tussen personen, panden en ondernemingen gevisualiseerd in een netwerk. Bij zo’n relatie kun je denken aan panden die in eigendom zijn van een persoon, personen die in een pand wonen, of personen die huisgenoten, familie, of collega’s zijn. Zo’n netwerk maakt grote hoeveelheden data visueel inzichtelijk, en helpt bij het signaleren van clusters, patronen, of de ‘spinnen in het web’.
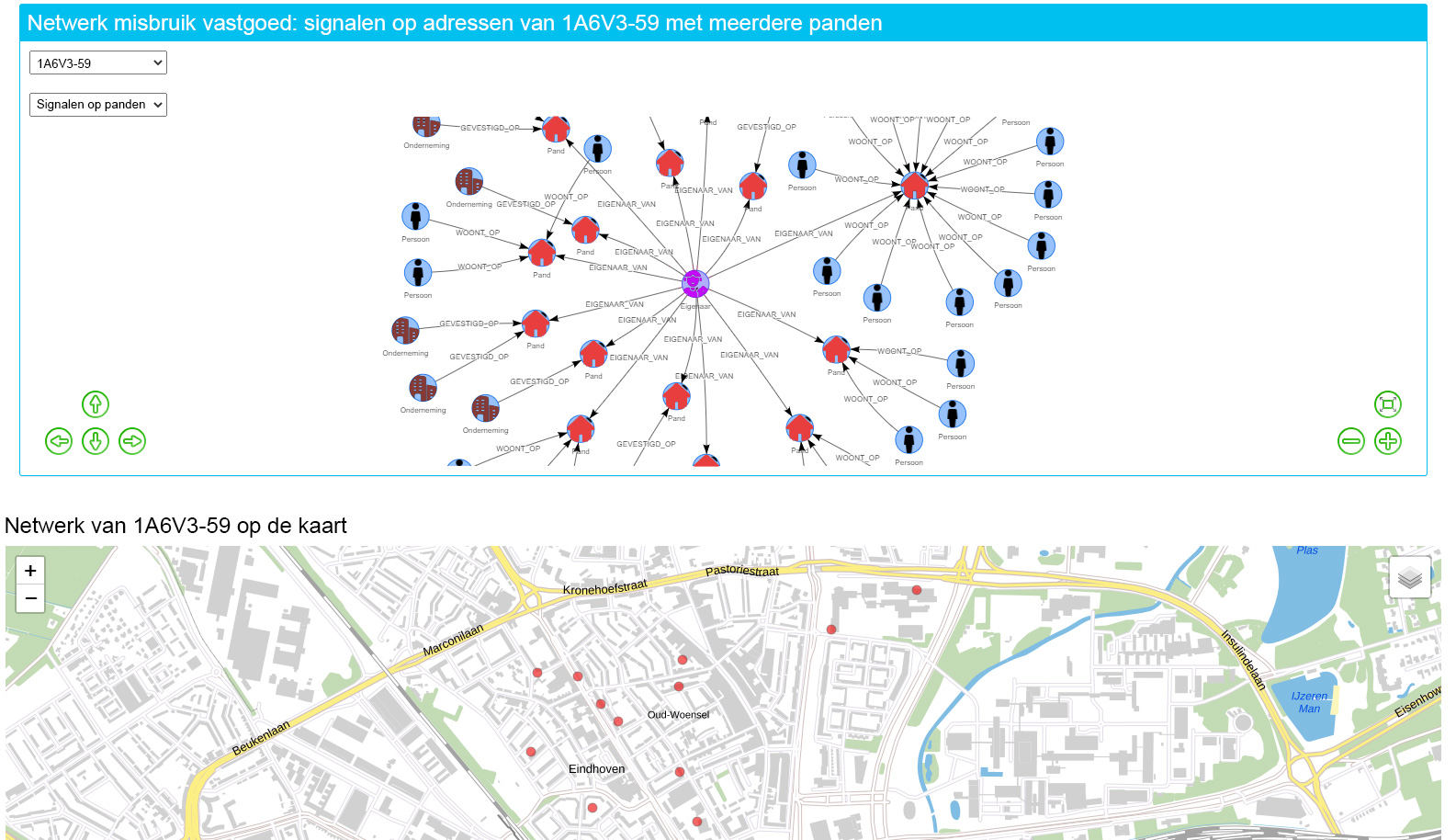
N.B. dit schermvoorbeeld is genomen van het prototype en is onderdeel van het resultaat van de Design Sprint. In het schermvoorbeeld zie je een gecombineerd beeld van een netwerkstructuur en de locaties op de kaart. In het netwerk is een analyse gedaan op individuen die in het bezit zijn van meerdere panden waarop signalen gemeld zijn die betrekking hebben op misbruik vastgoed. Deze persoon in kwestie heeft dus meerdere panden met een score op de benoemde indicatoren. Onder het netwerk is bovendien een kaart zichtbaar waar de panden geografisch weergegeven zijn. Nb: de locaties van de panden zijn fictief en puur ter illustratie op deze manier weergegeven. Wij hebben bij de Design Sprint geen persoonsgegevens of tot locatie- of personen herleidbare gegevens gebruikt.
We kijken terug op twee interessante Design Sprints rondom het thema misbruik van vastgoed. Dit thema is één van de landelijke thema’s in de bestrijding van ondermijning en bood ons daarmee een mooie kans om ons opnieuw te verdiepen in de exploitatie en speculatie van vastgoed. Het thema vastgoedmisbruik is met name ook interessant met het oog op privacy. We hebben tijdens deze sprints daarom veel aandacht besteed aan het omgaan met geanonimiseerde data, en aan het verkennen van de mogelijkheden om de uitgangspunten van een privacyprotocol te verankeren in een analyse-instrument. Als je vragen hebt of het prototype een keer wil zien, neem dan vooral contact met ons op. We vertellen je graag meer!
Whitepapers
Productinformatie
Nieuws
Blogs
Webinars
Praktijkcases
Research
Foto (boven) credits: Micheile Henderson op Unsplash.

Met 2020 achter ons (eindelijk!) wordt het zo langzamerhand tijd om weer vooruit te kijken. Van het afgelopen jaar hebben we geleerd dat sommige dingen niet te voorspellen zijn, maar dat weerhoudt ons er niet van toch een poging te wagen. Onze trendwatchers hielden hun ogen goed open, en in deze blog delen wij onze voorspellingen voor de belangrijkste ontwikkelingen voor het nieuwe jaar op het gebied van data science in het algemeen en de datagedreven overheid in het bijzonder. We identificeren technologische trends die interessant zijn voor de datagedreven overheid, maar bespreken ook belangrijke maatschappelijke ontwikkelingen die het gebruik van data beïnvloeden.
Machine learning is al lang geen noviteit meer. Het wordt voor allerlei toepassingen gebruikt. Het wordt bijvoorbeeld gebruikt om met steeds grotere nauwkeurigheid voorspellingen over het weer te kunnen doen. Ook deepfakes, de even fascinerende als beangstigende neppe videobeelden die ontwikkeld worden met behulp van deep learning algoritmes, zijn het resultaat van machine learning, Een belangrijke ontwikkeling op het gebied van machine learning is AutoML: automated machine learning. Bij AutoML gaat het om het automatiseren van het leerproces (machine learning experts zijn gek op automatiseren). Nu is het ‘voeden’ van een machine learning algoritme een arbeidsintensief proces dat veel menselijke expertise vraagt. Het kunnen automatiseren van dit proces zou betekenen dat machine learning in 2021 vaker en makkelijker toegepast kan worden, wat interessante gevolgen kan hebben voor haar vele toepassingsgebieden.

Machine learning wordt gebruikt voor een enorme range aan voorspellingen. Het afgelopen jaar zal een interessante les zijn voor experts in de wereld van machine learning: de Corona pandemie heeft laten zien dat voorspellingen heel kwetsbaar kunnen zijn, en dat de waarde van een voorspelling snel kan verdwijnen als de omstandigheden onverwachts veranderen. De robuustheid van voorspellende modellen is dus behoorlijk aan de tand gevoeld het afgelopen jaar. De economische crisis van 2008 leidde tot veel interessante onderzoeksvragen, zoals de vraag of we kunnen identificeren welke bedrijven het minst en het meest kwetsbaar zijn voor allerlei soorten externe shocks. De huidige crisis zal ongetwijfeld ook aanzetten tot nieuwe vragen over de kwaliteit en robuustheid van de voorspellende modellen die we gebruiken.
Sociale media zijn niet meer weg te denken uit ons dagelijks leven. Hierdoor heeft iedereen wel een beeld bij het begrip ‘sociale netwerken’. Zulke netwerken worden al jaren op grote schaal geanalyseerd. Bij sociale netwerken zijn de ‘bolletjes’ mensen, en de ‘streepjes’ de relatie tussen die mensen. Zo’n relatie kan van alles zijn: vriendschap of collega’s, maar ook bijvoorbeeld of ze samen in een film hebben gespeeld. Netwerken kan je analyseren om vragen te beantwoorden zoals ‘welke personen zijn centraal in dit netwerk?’ of ‘wat zou er gebeuren als er iemand uit het netwerk valt?’. Dat zijn niet zomaar vragen: stel je je een netwerk van terroristen of drugshandelaren voor, dan kan het aanpakken van de juiste persoon ervoor zorgen dat het hele netwerk uiteenvalt. Sociale netwerken worden al jaren geanalyseerd, maar er is zoveel meer. Wat gebeurt er bijvoorbeeld met een lange supply chain wanneer er een belangrijke schakel failliet gaat? Wat is het gevolg van de Coronacrisis voor het transactienetwerk van banken? Waar gaan mensen naartoe nadat ze op een specifieke plek in de stad zijn geweest? Hoe verhoudt een malafide bedrijf zich tot andere bedrijven? De ‘bolletjes’ in een netwerk kunnen dus ook bedrijven zijn, of gebouwen, of producten of iets anders, en de ‘lijntjes’ kunnen staan voor transacties, bewegingen, causaties, en eigenlijk iedere soort interactie zijn. Door data te zien als een netwerk (een ‘graph database’) in plaats van als een tabel, zoals we vaak gewend zijn te doen, komen er nieuwe interessante vragen aan het licht. Wij verwachten dat in 2021 de vraag naar netwerkanalyses flink zal groeien, en we deze aanpak steeds vaker kunnen toepassen in verschillende maatschappelijke domeinen.

‘X marks the spot’, en kan hier voor van alles staan. Het analyseren van nette, gestructureerde datasets gebeurt natuurlijk al heel lang. Het analyseren van andere dingen, zoals teksten uit krantenartikelen of boeken, video’s, afbeeldingen, geluidsfragmenten en taal, is zich ook sterk aan het ontwikkelen. Vul ieder van die dingen maar in op de X! In de wetenschap zijn er al veel inspirerende voorbeelden van text analytics, sound analytics en natural language processing. Mijn persoonlijke favorieten zijn een analyse van de tekst uit populaire volksverhalen die laten zien welke oude volksstammen met elkaar in contact waren en hoe ze over de wereld migreerden, en deze analyse die muziekfragmenten ziet als stukjes DNA. In de zakelijke en maatschappelijke wereld wordt er nog een stuk minder gebruik gemaakt van al deze verschillende soorten analyses. De potentie is er wel: wat als we geluidsfragmenten van uitgaansgebieden kunnen gebruiken om veiliger uit te gaan? Welke inzichten kunnen we krijgen als we op grote, structurele schaal social media en review sites gaan analyseren? Wat ons betreft valt er op dit gebied nog veel te ontdekken, en zou het zeer de moeite waard zijn om hier in 2021 verder in te duiken.
Waar ‘de Cloud’ eerst een hip buzzword was voor alles wat met internet te maken had, is het nu een begrip dat volwassen aan het worden is. Cloud computing is een manier van werken waarbij je geen gebruik maakt van je lokale machine, maar werkt met on-demand beschikbare servers waarop je bijvoorbeeld je data op kan slaan. Werken in de cloud biedt mogelijkheden voor ‘software as a service’ en ‘data as a service’: een businessmodel waarbij een product niet lokaal bij een klant geïnstalleerd wordt, maar wordt aangeboden als een dienst en waarbij je betaalt naar gebruik. De klant is daarmee dus niet eigenaar van het product. Deze manier van werken heeft een aantal serieuze voordelen voor zo’n klant: de service is makkelijk op- of af te schalen, er zijn geen aanschafkosten, en de maandelijkse of jaarlijkse kosten zijn heel inzichtelijk. Misschien wel het belangrijkste voordeel is dat onderhoud, uitbreidingen, klachten en storingen niet door de klant behandeld worden maar door de leverancier. Dat is handig, maar zorgt er vooral voor dat de leverancier er belang bij heeft om te zorgen dat de dienst goed werkt, gebruiksvriendelijk is, weinig storingen heeft, en lang meegaat. Heel wat anders dan het gemiddelde koffiezetapparaat, dus. Om die reden is het ‘XaaS’ (‘anything as a service’) businessmodel is niet alleen populair in de IT-wereld, maar wordt het ook steeds vaker gebruikt om bijvoorbeeld de mobiliteitswereld en de productie-industrie te verduurzamen. Voor data-projecten is het erg geschikt omdat het het mogelijk maakt om grote datasets en zware analyses uit te voeren zonder toegang tot een supersterke computer. De cloud is dus here to stay, en de mogelijkheden die dit biedt zullen in 2021 ongetwijfeld verder verkend worden.

Op technisch vlak zijn de mogelijkheden voor complexe modellen en geavanceerde analysemethodes bijna eindeloos. We kunnen onze computers zó vlijtig aan het werk zetten zodat zelfs de beste ontwikkelaar niet meer begrijpt wat er achter de schermen precies gebeurt. Zulke algoritmes zitten in een ‘black box’. Parallel aan de technologische ontwikkeling loopt ook een andere ontwikkeling: het maatschappelijke debat over of we dat eigenlijk wel moeten willen. Er wordt over de hele linie gepleit voor transparante AI, in twee vormen. In de eerste plaats is dat transparantie binnen algoritmes, waarbij het erom gaat dat algoritmes begrijpelijk blijven (‘explainable AI’, of XAI – ja, weer die X!). Daarmee voorkomen we besluitvorming op basis van black boxes, zorgen we ervoor dat menselijke experts kunnen blijven meedenken met het algoritme (‘human in the loop’) en de resultaten van een algoritme kunnen verantwoorden, en voorkomen we kwalijke zaken als biases in algoritmes. Een charmant voorbeeld van transparantie binnen algoritmes is de ‘waarom zie ik dit?’-knop die Facebook dit jaar toevoegde aan haar gepersonaliseerde advertenties. In de tweede plaats gaat het maatschappelijke debat over transparantie over algoritmes: welke algoritmes worden er eigenlijk gebruikt, en hoe beïnvloeden die onze levens? Eind september lanceerden Amsterdam en Helsinki samen het eerste algoritme register ter wereld, waarin de steden bijhouden welke algoritmes voor welke doelen gebruikt worden, en hoe deze algoritmes gebruikt, beveiligd en gecontroleerd worden. Zowel transparantie binnen algoritmes als transparantie over algoritmes staan echt nog in de kinderschoenen, en wij verwachten dat hier in 2021 veel aandacht voor zal zijn.

Een stap verder dan transparante AI is ‘responsible AI’ (je raad het al: RAI). Hierbij gaat het niet alleen om transparantie, maar ook om zaken als eerlijkheid, veiligheid, het waarborgen van privacy. De vele discussies over de Corona-app, met vragen als ‘kunnen we mensen verplichten tot het gebruiken van deze app?’ en ‘hoeveel moet zo’n app van ons weten om nuttig te zijn?’, lieten zien dat deze thema’s belangrijk en nog niet uitgekristalliseerd zijn. De vraag hoe eerlijk een algoritme is, wordt niet altijd expliciet gesteld. Het boek ‘Invisble Women: exposing data bias in a world designed for men’ dat het afgelopen jaar enorm populair was, benadrukte dat blinde vlekken of verkeerde aannames vaak aan de basis liggen van onbedoeld oneerlijke algoritmes. Wij verwachten dat er in 2021 veel aandacht gaat komen voor de vraag hoe we met data kunnen werken op een eerlijke, veilige en verantwoorde manier.
In Nederland lijkt de sinds 2018 geldende AVG langzaam volwassen te worden. Gemeentes werken met privacy officers, en voor projecten die met data van doen hebben zijn protocollen opgesteld. De komende jaren zal gaan blijken in welke situaties deze aanpak goed werkt, en waar nieuwe kansen liggen. Ook internationaal verwachten we veel aandacht voor responsible AI. De fascinerende maar soms ook shockerende voorbeelden van ‘deep fakes’ die ik al eerder noemde laten zien dat er ook internationale aandacht nodig is voor het verantwoordelijk gebruiken van data en algoritmes, en voor het beschermen van personen en hun identiteit.

Design thinking is een werkwijze die populair is in de design-hotspots van de wereld, zoals Silicon Valley en ons eigen Eindhoven. Onze Design Sprints zijn er een goed voorbeeld van. Design thinking is een iteratieve aanpak waarbij de gebruiker centraal staat, en waarbij oplossingen voor uitdagingen gezocht worden door eerst het probleem vanuit verschillende perspectieven te bekijken. Het is een interessante aanpak, omdat het uitnodigt om ‘om te denken’ en bestaande aannames tegen het licht te houden. Dat is belangrijk, gegeven de grote hoeveelheid aandacht voor eerlijke en ‘explainable’ algoritmes en veilig gebruik van data. Omdat het een werkwijze is die de gebruiker centraal stelt en die veel aandacht besteedt aan het integraal belichten van op te lossen maatschappelijke problemen, verwachten wij dat design thinking een steeds grotere rol gaat spelen.
Gerelateerd hieraan is de trend ‘van dashboard naar story’ die wij steeds vaker horen: waar het de afgelopen jaren populair was om instrumenten te ontwikkelen waarbij gebruikers zelf met data kunnen werken om hun eigen visualisaties te maken, wordt de vraag naar ‘data stories’ steeds groter. Men is zich er steeds meer van bewust dat data altijd een verhaal vertelt, en dat het belangrijk is om dit verhaal zorgvuldig te interpreteren, in de juiste context te plaatsen, en te laten passen bij de doelgroep. Vandaar dat wij verwachten dat het dashboard, de zandbak waarin gebruikers zelf bouwen, steeds vaker plaats zal maken voor data stories, waarbij data in dienst staat van een maatschappelijk doel.
Van oudsher zijn de werelden van de mens en de wereld van de techniek behoorlijk gescheiden. Je kan psychologie, sociologie of geschiedenis studeren om de mens te bestuderen, en werktuigbouwkunde of computer science om de techniek te begrijpen. Er zijn maar weinig plekken waar je leert over de interactie tussen mens en techniek. Op dezelfde manier was ook de wereld van de ‘kwalitatieve data’, de wereld van boeken en interviews, gescheiden van de wereld van de ‘kwantitatieve data’, de wereld van tabellen en grafieken. Nu zien we steeds meer dat die werelden naar elkaar toe beginnen te groeien. Aan de ene kant komt dat doordat kwantitatieve data op zo’n grote schaal wordt verzameld, ingezet en gecommuniceerd dat niemand er nog omheen kan. Ook iemand die liever alles wat eruitziet als spreadsheets zoveel mogelijk vermijdt, moet nu enige datageletterdheid hebben om te kunnen deelnemen aan maatschappelijke discussies. Aan de andere kant zorgen diezelfde maatschappelijke discussies ervoor dat we van algoritmebouwers verwachten dat zij op de hoogte zijn van meer dan alleen de techniek: zij moeten ook meekunnen als het gaat om gebruiksvriendelijkheid, privacy, hun eigen aannames, en het effect dat het gebruik van hun algoritmes heeft op het gedrag van mensen en de maatschappij. Ook in onze data-applicaties zien wij mens en techniek naar elkaar toe groeien. Zo horen we bijvoorbeeld steeds vaker dat onze gebruikers een plek zoeken om naast ‘harde data’ ook ‘zachte data’ met elkaar te delen: conclusies uit gesprekken, voornemens tot maatregelen en andere inzichten geven onmisbare context aan modellen die op basis van ‘harde data’ zijn ontwikkeld. De twee werelden zijn geheel complementair, en we zien deze ontwikkeling zich graag voortzetten in 2021.

De toepassing van data science technologieën raakt steeds verder verankerd in besluitvormende processen. Dat wil natuurlijk niet zeggen dat er beleid geformuleerd wordt puur op basis van voorspellingen uit modellen. Het is wel zo dat in veel fases in het besluitvormingsproces een informerende rol voor data science is weggelegd. In de eerste plaats begint de verkenning van nieuw beleid vaak met de (logische) vraag ‘wat is de huidige situatie rondom dit thema?’ Het slim inventariseren en visualiseren van beschikbare data speelt steeds vaker een rol bij het beantwoorden van die vraag. Daarmee is dan direct ook een tweede vraag beantwoord: ‘wat is de status van beschikbare informatie/data rondom dit thema?’ Dat is een relevante vraag, want een goede datahuishouding biedt vaak nieuwe mogelijkheden om die data te gebruiken om een maatschappelijk probleem op te lossen, of ten minste om geen tijd te verspillen aan inefficiënt werken. Ten tweede is er een duidelijke rol voor data-analyse weggelegd in het monitoren en evalueren van beleid. Ten derde kan data science helpen bij het identificeren van vruchtbare gronden voor nieuw beleid. Zo kan een statistische analyse aangeven of er een relatie is tussen twee factoren, en of die relatie positief of negatief is. Zo’n analyse kan inzicht geven in mogelijke effecten van een nieuwe maatregel. Gezien de complexiteit en onvoorspelbaarheid van maatschappelijke problemen denken wij dat het gebruik van scenario’s geïnformeerd door data science een vlucht gaat nemen in 2021. Het gebruik van scenario’s sluit namelijk ook uitstekend aan bij de trend richting data stories, en lijkt ons ook gewoon hartstikke interessant!
Het inventariseren, analyseren en visualiseren van data is natuurlijk al interessant en nuttig in zichzelf. Naast dat dit tot interessante nieuwe inzichten kan leiden, zien wij ook steeds vaker dat data-analyse kan bijdragen aan het doorbreken van silo’s. Ik noemde al eerder dat wij merken dat onze data-applicaties de werelden van de ‘harde’ en de ‘zachte’ data dichter bij elkaar brengt. Op dezelfde manier geloven wij dat data ook verschillende domeinen bij elkaar kan brengen. Zo draagt data bij aan een integrale aanpak van maatschappelijke problemen, wat goed past bij domein-overstijgende thema’s zoals gebiedsgericht werken. We horen bijvoorbeeld vaak dat verschillende gemeentelijke domeinen ieder hun eigen ‘taal’ hanteren. Door je gezamenlijk te buigen over data-inventarisatie en data-visualisatie, worden in de eerste plaats deze verschillen zichtbaar en kunnen we ervoor zorgen dat er een gedeeld begrip gaat ontstaan. Ook hierbij verwijzen we terug naar ons eerdere punt over design thinking en data stories: hoe kunnen we door middel van data een verhaal vertellen dat aansluit bij de leefwereld van anderen, en zo onze werelden wat dichter bij elkaar brengen? In onze recentere projecten zien wij dit in de praktijk, en we hopen van harte dat deze ontwikkeling zich doorzet in 2021.
Tijdens mijn onderzoek naar trends en ontwikkelingen in data science voor deze blog viel het mij op hoeveel van deze trends te maken hebben met het bij elkaar brengen van verschillende werelden, en de belangrijke rol die data daarin kan spelen. Dat lijkt mij een ambitie die in haar geheel mee mag naar 2021, en een uitstekende gedachte om deze blog mee af te sluiten! Dus, moge 2021 het jaar zijn waarin verschillende werelden (weer) voor je open gaan dan wel samen komen!
Wil je automatisch op de hoogte blijven van onze digitale content? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via dit formulier en vink de ‘blog’ optie aan!
Whitepapers
Blogs
Academy
Testimonials
Masterclasses
Foto (boven) credits: Samuel Chenard op Unsplash

Na maanden zonder evenementen, groepen mensen of überhaupt maar fysieke meetings was er eindelijk weer ruimte voor een heus congres. Op 16 september jl. organiseerde het Studiecentrum voor Bedrijf en Overheid de 5e editie van het Congres Ondermijning en Georganiseerde Criminaliteit. Strakke handhaving van de 1,5 meterregel kunnen we aan veiligheidsexperts natuurlijk goed overlaten, maar (net)werkt dat ook een beetje? En nog belangrijker: wat zijn de grote thema’s die aan bod kwamen?
Als voormalig promovenda ben ik een behoorlijk doorgewinterde conferentieganger. De conferenties waar ik kwam waren vaak behoorlijk breed van onderwerp (‘evolutionary economics’) en trokken figuren van allerlei pluimage aan. Dat maakt de praatjes fascinerend, maar niet per se relevant. Dit was mijn eerste conferentie die gericht is op professionals in plaats van academici, en waar mensen hun praktijkervaringen delen in plaats van hun papers. Waar ik dus vooral nieuwsgierig naar was: kan ik mijn inzichten tijdens dit congres nu echt toepassen op mijn werk. Daarnaast was ik benieuwd naar wat op dit moment de belangrijkste thema’s rondom ondermijning zijn, en vroeg ik me af hoeveel mensen ik nou echt zou kunnen ontmoeten tijdens een congres op 1,5m afstand.
Natuurlijk zijn er veel verschillende thema’s aan bod gekomen. Zo is daar altijd de roep om samenwerking en een integrale aanpak. De burgemeesters van Antwerpen en Turnhout zeiden overigens dat ze jaloers waren op de Nederlandse aanpak. Die opmerking illustreert de complexiteit van ondermijning, want des te beter wij het in Nederland doen, des te meer zij last hebben van het resulterende waterbedeffect. Ook wetgeving en het veilig en verantwoord omgaan met privacygevoelige informatie werden veel besproken. Drie thema’s wil ik er specifiek uitlichten: de onzichtbaarheid van ondermijnende criminaliteit, de kanarie in de kolenmijn, en a problem well stated is a problem half solved.
Hoewel dit congres eigenlijk voor een Nederlands èn Vlaams publiek bedoeld is, moesten de meeste Vlamingen het in verband met het Coronavirus jammer genoeg laten afweten. Het publiek van dit congres bestond voornamelijk uit medewerkers van (Nederlandse) gemeentes en mensen van de politie. Op de vraag wat volgens de deelnemers nou het meest ondermijnende effect van georganiseerde criminaliteit is, vond ik de antwoorden opvallend eenduidig. Een groot deel van het publiek noemde onzichtbaarheid als meest ondermijnende factor, wijzend op de subtiele manier waarop boven- en onderwereld verstrengeld raken zonder dat we het merken. Veel vormen van ondermijnende criminaliteit gebeuren voor je neus zonder dat je het doorhebt, of vinden plaats achter de voordeur. En, zo merkten verschillende mensen in het publiek op, zelfs als de effecten van ondermijning in sommige gevallen toch zichtbaar worden, blijven de echte daders buiten beeld. Ik kan mij voorstellen dat dit de handhavers en de beleidsmakers in de zaal enorm frustreert. Naast onzichtbaarheid werd ook normvervaging veel genoemd: het langzaamaan normaal worden van abnormaal gedrag.
Zoals ik eerder al zei, heb ik geprobeerd mij af te vragen wat onze rol als data scientists hier kan zijn. Hoewel ik het lastig vind om een thema als normvervaging te duiden, is de onzichtbaarheid van ondermijning natuurlijk iets wat wij ons erg aantrekken. Het op een veilige, betrouwbare en slimme manier verzamelen, analyseren en visualiseren van data kan namelijk een belangrijk instrument zijn, daar waar onze eigen zintuigen te kort schieten!
De eerste spreker, de Zweedse criminoloog dr. Amir Rostami, wees er al op: let op de vroege signalen, en neem die signalen serieus, ook als ze niet alarmerend zijn of onbetrouwbaar lijken. Rostami noemde dat de aanwezigheid van motorclubs vaak een vroeg signaal van straatbendes zijn. Dat vond ik in eerste instantie moeilijk te geloven, omdat motorclubs een heel andere doelgroep hebben dan straatbendes. Zou het iets te maken hebben met een onderliggende maatschappelijke structuur die criminele subculturen faciliteert? Volgens Rostami niet – volgens zijn onderzoek is er een veel directere link tussen motorbendes en andere groepen lawbreakers zoals voetbalhooligans, gangs, en politieke of religieuze extremisten. Hij analyseerde een ecology of lawbreakers (wat mij als evolutionair econoom slash netwerkanalist bijzonder aanspreekt): een netwerk van personen die samen een misdaad plegen (co-offending), gegroepeerd op de verschillende criminele organisaties die ze aanhangen, en vond iets opvallends: motorbendes hebben een brugfunctie tussen de andere groepen lawbreakers. Motorclubs hebben dus wel degelijk iets te maken met straatbendes: ze vormen een voedingsbodem. Geen wonder dus dat ook Cedric Stuyck, sectiehoofd Georganiseerde Misdaad van Belgisch Limburg, er in zijn verhaal erop wees dat Outlaw Motorcycle Gangs (OMG’s – ja!) een faciliterende rol tussen andere criminele groepen hebben. Een vroeg signaal dat wellicht niet meteen alle alarmbellen doet afgaan is dus het onderzoeken waard, want misschien liggen de relaties complexer dan ze lijken. Ook Shanna Mehlbaum, onafhankelijk onderzoeker en criminoloog, benadrukte dat onderbuikgevoelens eigenlijk altijd terecht blijken te zijn. Deze moeten dus niet worden afgedaan als ongefundeerd of onbetrouwbaar, maar verdienen het om opgepakt te worden. Paul van Miert, de burgemeester van Turnhout zei treffend ‘als het regent in Antwerpen, dan drupt het in Turnhout.’
De bal ligt hier volgens mij voor een groot deel bij data scientists en andere analisten. Zij kunnen namelijk een belangrijke taak vervullen door vroege of onopvallende tekenen te signaleren en, misschien nog wel belangrijker, te onderzoeken wat die tekenen dan zouden kunnen zijn. Signalen zoals flinke toenames in lokale vestigingen van bedrijven uit criminogene branches zijn ons wel bekend, maar er zijn ongetwijfeld ook early warnings waar wij nog niet aan gedacht hebben! Het lijkt mij ook erg interessant om te onderzoeken welke rol data scientists kunnen hebben bij dat ‘onderbuikgevoel’. Per definitie is dat namelijk iets wat moeilijk te duiden is. Kan data helpen om onderbuikgevoelens te onderbouwen? Of kunnen we onderbuikgevoelens op een betekenisvolle manier visualiseren, zodat het de aandacht krijgt die het verdient?
Ook dit thema werd als eerste benoemd door dr. Amir Rostami. Hij zei dat er vaak te snel naar een ‘oplossing’ wordt gegrepen, zonder dat eerst uitgebreid besproken wordt wat het probleem nou eigenlijk is, hoe groot het probleem is, en voor wie het een probleem is. Ook mijn Nederlandse gesprekspartners tijdens de lunchpauzes herkenden dit. Ik vond dat dr. Robby Roks die aan de Erasmus Universiteit onderzoek doet naar internationaal drugstransport in de haven van Rotterdam een mooi voorbeeld gaf van een problem well stated. Hij werkt met crime scripts – een soort stripverhalen die een model vormen voor veelvoorkomende patronen in criminaliteit (zie ook een van onze eerdere blogs hierover). Voor internationale drugshandel gaf hij daarmee aan dat dit probleem eigenlijk niet één maar drie problemen zijn: ten eerste, drugshandel waar drugs verstopt zit in een container of sporttas, ten tweede drugshandel waarbij drugs verstopt zit in het handelswaar, zoals bananen en ananassen, en ten derde drugshandel waarbij drugs verstopt zit op het schip zelf. Specifiek voor ieder van deze drie patronen kon hij zwakke plekken op de Rotterdamse haven aanwijzen. Ik zou niet durven beweren dat het probleem daarmee half solved is, maar een goed begin is het halve werk. Of ja, minder dan de helft, dus.
Ook voor dit thema zie ik een rol weggelegd voor ons als data scientists. Vaak verwacht men van data dat er heel complexe modellen en kamers vol computers nodig zijn om tot nieuwe inzichten te kunnen komen. In de praktijk is dat vaak niet zo: alleen al het zorgvuldig inventariseren van de beschikbare informatie en het op een intelligente manier weergeven ervan kan veel prangende vragen oplossen. Met andere woorden: waar we data kunnen inzetten om bijvoorbeeld te voorspellen waar de volgende drugsdumping kan zijn, zou altijd de eerste stap moeten zijn om te inventariseren hoeveel drugsdumpingen er eigenlijk zijn geweest, wat er gedumpt wordt, waar dat vandaan komt.
Er waren niet meer dan 80 gasten welkom bij dit congres, zodat de afstand te allen tijde goed bewaakt kon worden. In de zalen stonden de stoelen in een strak raster opgesteld. Voor tijdens de pauzes waren stoelen neergezet in de lounge, zodat iedereen plek heeft aan een tafel. Drankjes werden uitgeserveerd aan tafel en niet aan de bar, en borrelhapjes mocht je alleen oppakken met een servetje. Onder het mom van ‘nieuwe mensen leren kennen’ waren alle bezoekers met een oranje of blauwe sticker op hun naamkaartje ingedeeld in twee groepen, met ieder hun eigen designated zone, afgezet met oranje of blauwe ballonnen.
Voor mij, als iemand die nieuw is in deze community, was dat eigenlijk best prettig. Ik hoefde me niet bij drukbevolkte statafels naar binnen te kletsen, en een soepele openingszin ligt altijd klaar (‘wel gek hè, die afstand?’). Het is natuurlijk ook wel echt gek. Waar ik normaal toch zeker een dozijn handen zou schudden bij een evenement zoals dit, waren dat er nu misschien vijf geweest. Waar je normaal voorgesteld zou worden aan elkaars collega’s (‘Daar hebben we Klaas, die doet ook iets met data!’), moet je het nu treffen met je toevallige tafelpartner waar je de hele pauze aan vast zit. (Gelukkig hadden ze voor gezellige gespreksstarters gezorgd voor als je het even niet getroffen hebt – ik had ze niet nodig, gelukkig.)

Voorbeelden van gespreksstarters
Een ander nadeel vind ik dat een deel van de sprekers nu digitaal inbelden. Op zich een goede oplossing natuurlijk, maar het is jammer dat je zo’n spreker dan niet in de pauze kan benaderen om verder te praten. Toch vind ik een congres als deze nu de moeite waard. Dit congres heeft wel laten zien dat het mogelijk is om een fysiek evenement te organiseren op een veilige en verantwoorde manier en dat dat toch zeker beter is dan het digitale alternatief!
Whitepapers
Productinformatie
Nieuws
Blogs
Webinars
Praktijkcases
Research

Wij zien de Design Sprint als een ideale manier om te innoveren en te starten met datagedreven werken in de publieke sector. Bij de oorspronkelijke Shintō Labs Design Sprint is het de bedoeling om met een klein team een aantal dagen intensief met elkaar te werken aan een oplossing in een afgesloten ruimte. Helaas ziet de wereld er in 2020 heel anders uit en is het geen vanzelfsprekendheid meer om fysiek bij elkaar te komen. Dat vergt enige uitdaging met het organiseren van Design Sprints.
Tegelijkertijd biedt het ook kansen om meer interactief en digitaal samen te werken. Wij zijn namelijk van mening dat de Shintō Labs Design Sprint ook online gehouden kan worden, zonder af te doen aan onze belofte: binnen vijf dagen ontwerpen en toetsen we een werkend prototype. Sterker nog, Remote Design Sprints hebben zelfs een aantal stevige voordelen boven fysieke sprints! In deze blog delen wij onze ervaringen, tips en oplossingen voor het doen van online Design Sprints.
Wij krijgen regelmatig de vraag of design sprints ook digitaal kunnen. Maar wat is het belangrijkste verschil tussen een digitale Design Sprint en een fysieke Design Sprint? We bespreken in deze blog twee varianten van de design sprint:de fysieke Design Sprint, en de digitale Design Sprint (of remote Design Sprint). Het zal geen verrassing zijn dat het voornaamste verschil tussen een fysieke en een digitale Design Sprint is dat het sprintteam bij een fysieke sprint vijf dagen lang gezamenlijk in één ruimte werkt aan de sprint, terwijl bij een digitale Design Sprint het sprintteam in een digitale ruimte, zoals Teams, Zoom of GoToMeeting, samenkomt. Dat kan nodig zijn omdat het team thuis werkt in verband met het Coronavirus, maar bijvoorbeeld ook omdat verschillende teamleden in verschillende uithoeken van Nederland wonen. Een derde variant is de hybride Design Sprint. Bij een hybride Design Sprint worden bepaalde onderdelen digitaal gedaan en andere onderdelen fysiek, of zijn sommige leden van het sprintteam fysiek aanwezig en anderen digitaal. Naast het gebruik van software zoals Teams zijn er eigenlijk weinig grote verschillen tussen de fysieke en de digitale Design Sprint – de dagindeling, de voorbereiding, en het resultaat zijn bijna hetzelfde.
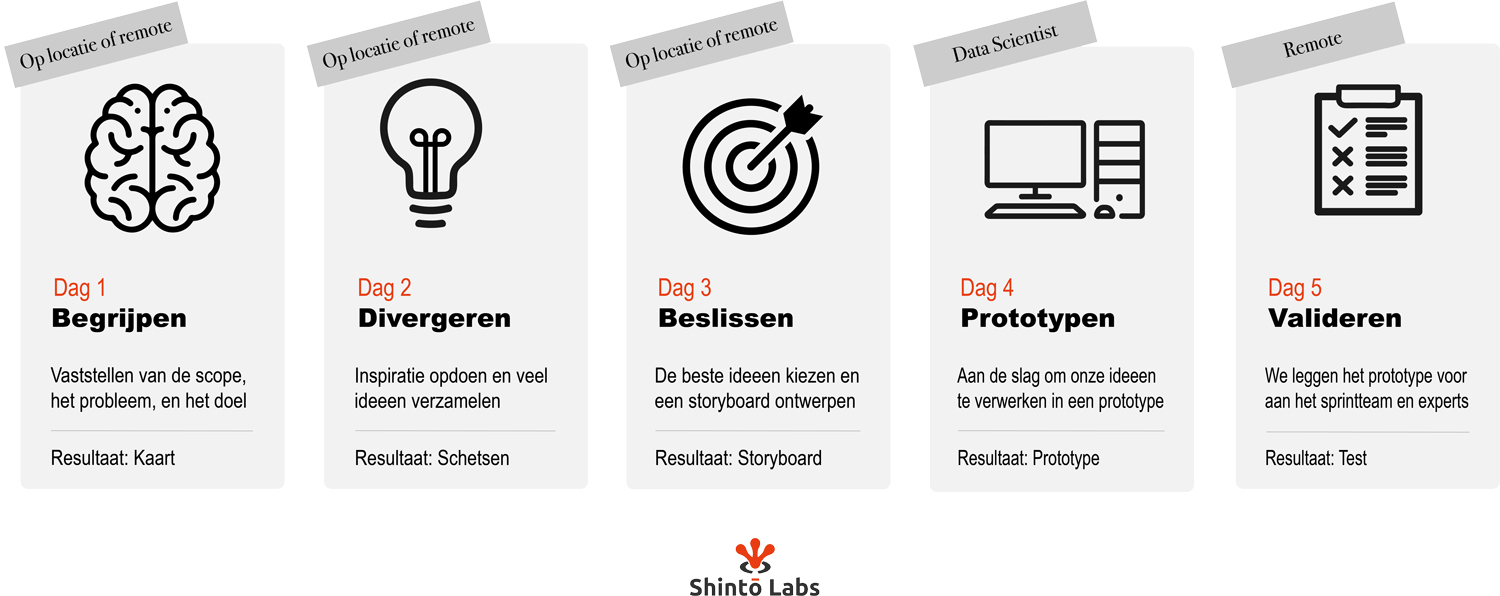
Shintō Labs Design Sprint
De afgelopen maanden hebben we allemaal gemerkt dat als het hele team thuis werkt, brainstorms en andere creatieve sessies vaak worden uitgesteld ‘tot we weer op kantoor zijn’, of toch niet zo soepel verlopen als we gewend zijn. Een (digitale) Design Sprint kan dan goed helpen om de discussie te structureren en om ideeën om te zetten in acties. Natuurlijk vinden wij het ook prettig om een paar dagen samen met een enthousiast team ‘in een hok te zitten’. Intensief samenwerken, kwartjes zien vallen, en het creëren van een goede sfeer zijn inspirerende aspecten van een Design Sprint. We zullen dus niet ontkennen dat een remote Design Sprint qua vibe wat lager scoort dan een fysieke sprint. We durven wel te beweren dat het inhoudelijke resultaat van een remote Design Sprint – een gedeeld begrip van een complex probleem, een verzameling mogelijke oplossingen, en natuurlijk een gevalideerd prototype – gelijk is aan dat van een fysieke Design Sprint. Een Design Sprint gaat immers niet alleen om het bij elkaar brengen van mensen, maar vooral om het bij elkaar brengen van ideeën, en die passen gelukkig wèl door een glasvezelkabel.
Wellicht voor velen gesneden koek, voor anderen is het altijd nog steeds wennen: het online videobellen. Zeker met een remote Design Sprint is het van belang dat we de etiquette goed volgen om niet afgeleid worden door omgevingsgeluid zoals het balken van een ezel uit de tuin van de buurman (echt!), een slechte verbinding, onnodige discussies en andere ongemakkelijkheden. Bij een fysieke Design Sprint leggen wij ook altijd bij de introductie de ‘spelregels’ uit van de werkdagen. Ook bij Remote Design Sprints gelden spelregels om het geheel effectief en efficiënt (en niet onbelangrijk), plezierig te houden. Dit zijn in de basis de online etiquette voor video bellen en voor de zekerheid zetten wij het nog even op een rijtje:
De Basics

Online videobellen: etiquette
Gedurende de sessies

Etiquette deel 2: gedurende de sessies
Het vertalen van de fysieke Design Sprint naar een remote Design Sprint kent een aantal obstakels. In de eerste plaats hechten we bij een fysieke Design Sprint veel waarde aan whiteboards, post-its, stiften en stapels papier. Er wordt veel getekend en geschreven, zowel door de sprintmaster als door de andere deelnemers, en alles wat we op papier zetten blijft gedurende de hele sprint toegankelijk ter inspiratie. Sinds de komst van software als Mural en Mira is dit gelukkig geen serieus obstakel meer. Deze software levert digitale whiteboards waaraan alle deelnemers vanaf hun eigen computer kunnen bijdragen. Bijkomende voordelen van zulke software is dat er oneindig veel ruimte is; we gebruik kunnen maken van ons eigen Design Sprint template om ons proces te structureren; en we aan het eind van de sprint met één muisklik een overzichtelijke rapportage van de hele sprint kunnen vastleggen!
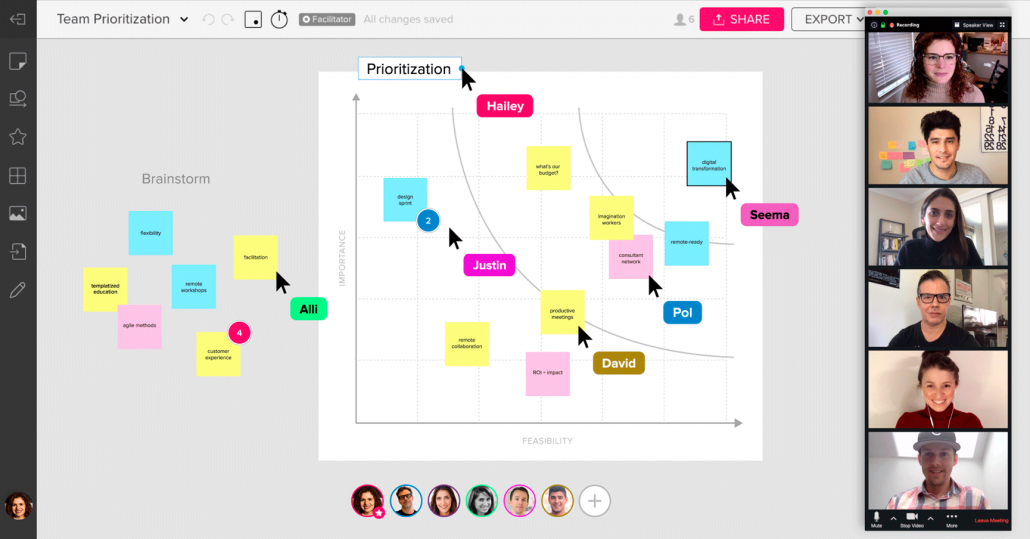
Screenshot brainstormen met Mural
Een ander obstakel is dat het nou eenmaal behoorlijk vermoeiend is om lang achter elkaar achter een beeldscherm te zitten en digitale discussies te voeren. Bij een digitaal gesprek is het altijd net even wat ingewikkelder om te beoordelen of een ander al is uitgepraat, en zijn er meer afleidingen. Om met dit nadeel om te gaan hebben we de werkvormen die we gebruiken bij een design sprint aangepast. Waar we bij een fysieke sprint open gesprekken niet schuwen, proberen we bij een remote design sprint de balans te vinden tussen individuele en collectieve activiteiten. Zo zullen we jullie bijvoorbeeld vragen eerst zelf een aantal sprintvragen op te schrijven en te beoordelen, en deze daarna pas aan de rest van de groep voor te leggen. Daarnaast houden we ook wat vaker pauze.
Een groot voordeel van een remote Design Sprint ten opzichte van een fysieke sprint is dat afstand geen probleem meer is. Dat klinkt triviaal, maar het biedt ongekende voordelen: sprintteamleden hoeven niet samen op één plek te zijn, dus we kunnen sprintteam-leden, experts en testers uit het hele land (en daarbuiten) uitnodigen (!).
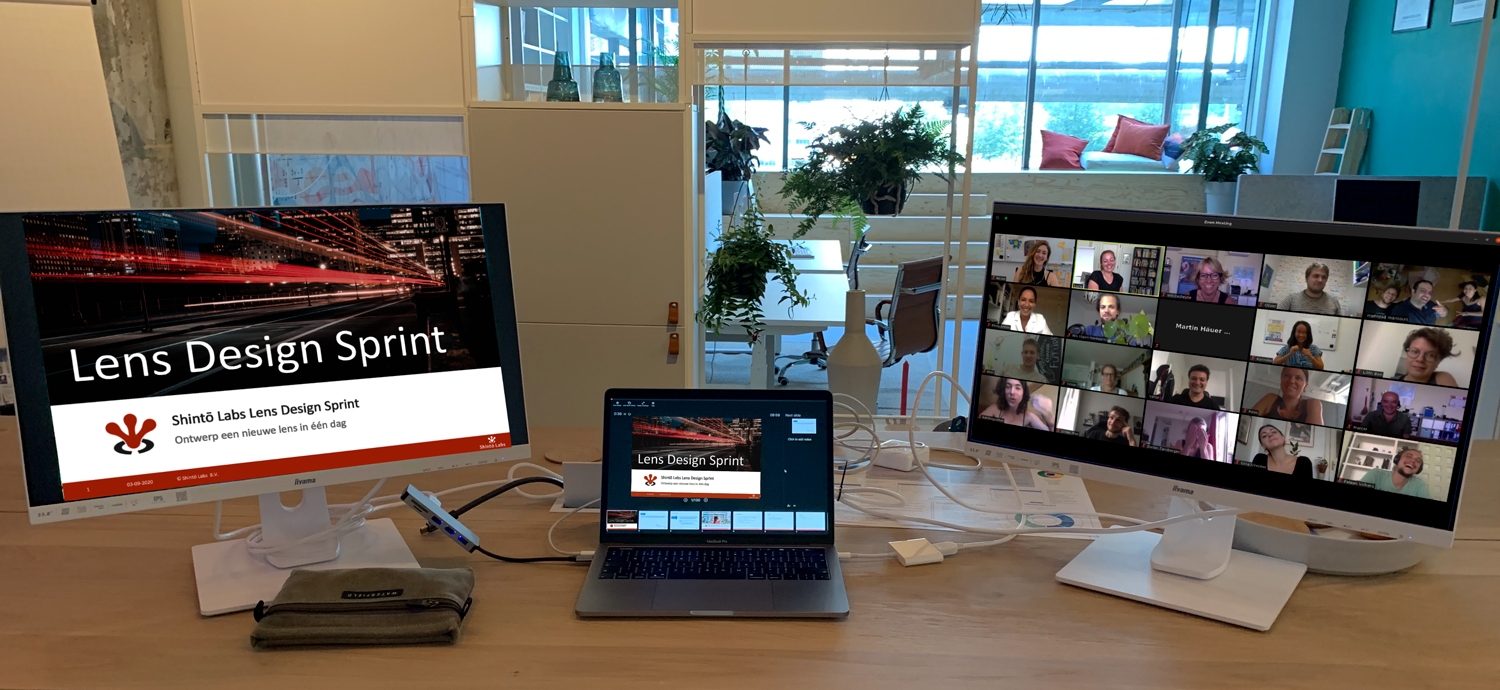
Digitale setup voor online Design Sprint
Al onze klanten zijn – naast het resultaat – ook altijd zeer te spreken over de energie en het plezier dat ze beleven aan een Design Sprint. Die energie is en het plezier is bij een Remote Design Sprint lastiger vast te houden, maar niet onmogelijk. Een aantal tips en trucs die we hebben gekregen van deelnemers, andere sprint masters en docenten van universiteiten die inmiddels ook bij ons een plek hebben gekregen bij de Remote Design Sprint.
Jazeker! De Corona-pandemie heeft ons gedwongen met een frisse blik naar onze Design Sprints te kijken, maar het concept van remote design sprinten of hybride design sprinten is niet nieuw voor ons. Zo hebben we gemerkt dat het voor de data scientist die het prototype gaat bouwen nuttig kan zijn om een gedeelte van de design sprint remote aanwezig te zijn. Op die manier kan de data scientist bijdragen aan het sprintproces en tegelijkertijd voorbereidend werk doen voor het bouwen van het prototype, zoals het verzamelen van data of het klaarzetten van een aantal onmisbare onderdelen van het prototype. Ook worden de validatiesessies op dag 5 vaak digitaal gedaan. Dat is handig wanneer we met grote groepen te maken hebben, of bijvoorbeeld met testers vanuit verschillende Nederlandse gemeentes.

Sprintmaster Mignon Wuestman bezig met het onderdeel Value Proposition Design
In onze ervaring is het niet ongebruikelijk dat sprintdagen 1 tot 3 fysiek zijn, en sprintdagen 4 en 5 geheel digitaal. In de praktijk bekijken we per sprint wat de goede balans is tussen fysieke en digitale activiteiten. Ons uitgangspunt daarbij is niet dat fysieke design sprints beter zijn dan digitale design sprints: waar sommige onderdelen of werkvormen beter uit de verf komen bij een fysieke bijeenkomst, komen andere onderdelen juist digitaal beter tot hun recht!
Omdat er bij een remote sprint sneller ter zake wordt gekomen en lange digitale discussies minder inspirerend kunnen zijn, kan het verleidelijk zijn om de Design Sprint in te korten naar 3 of 4 dagen in plaats van 5. Wij raden dit niet aan. De Big Challenge waar we mee aan de slag gaan is immers nog even complex, en het goed verkennen van die challenge en mogelijke oplossingen ervan kost tijd. Daarnaast kost kennismaken met elkaar en de digitale omgeving en effectief en geconcentreerd communiceren via een beeldscherm juist meer tijd dan bij een fysieke sprint. Alleen wanneer het onderwerp van de sprint zich leent voor een ingekort programma, zoals bijvoorbeeld bij een Lens Design Sprint, raden we aan de sprint in te korten.
Als jullie tips hebben voor ons, mail ze naar mij op mignon@shintolabs.nl
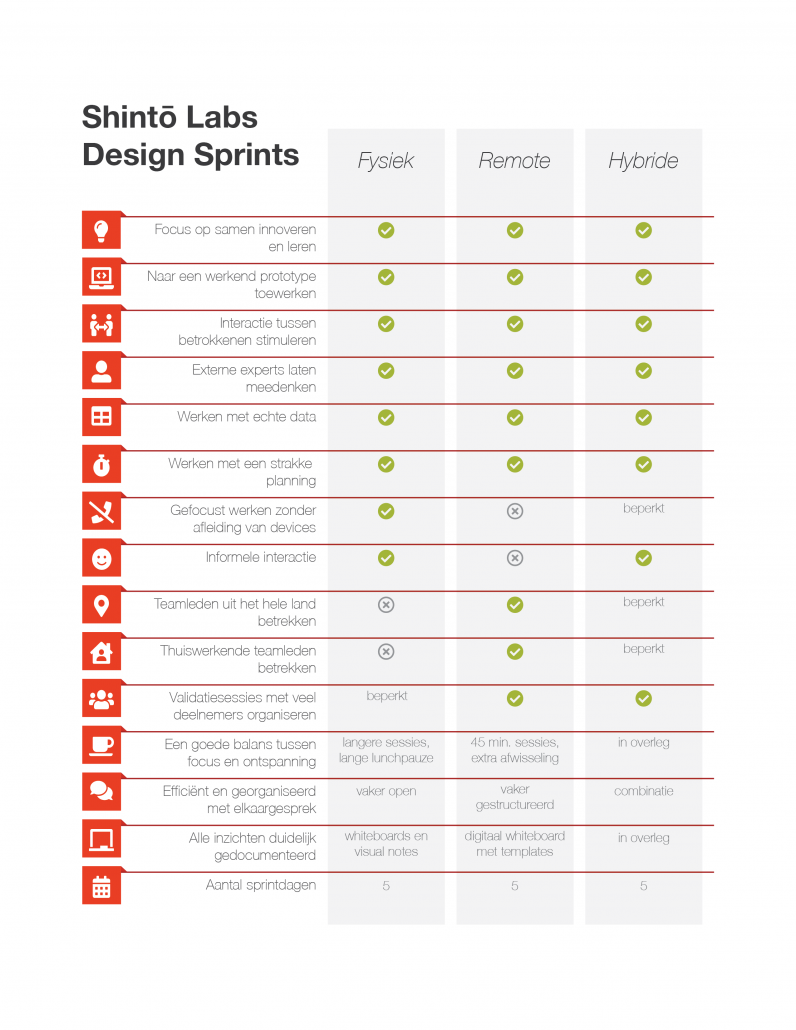
Overzicht verschillen fysiek vs remote vs hybride Design Sprint
Wil je meer weten over (remote) Design Sprinten? Laat het ons dan weten via onderstaand formulier!
Wil je automatisch op de hoogte blijven van onze digitale content? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via bovenstaand formulier en vink de ‘blog’ optie aan!
Whitepapers
Blogs
Academy
Testimonials
Photo credits Chris Montgomery on Unsplash

Deze maand zijn we gestart met een serie video’s waarin we onze kennis delen onder de noemer: Shintō Labs Masterclass. In iedere editie komt een expert aan het woord om over een specifiek onderwerp zijn of haar kennis te delen. We gaan in op verschillende vraagstukken rondom datagedreven werken en data analytics in de overheid. Onderwerpen kunnen variëren van innovatie methodiek, privacy, ethiek maar ook meer technische onderwerpen als text analytics en graph databases.
In deze editie vertelt data scientist Wesley Brants over over het opsporen van verdachte netwerken in gemeentelijke data. Aanbod komen onderwerpen zoals netwerktheorie, netwerk analyse, crime scripts en organized crime lab. Naast uitleg over de werking van graph databases worden ook voorbeelden uit onze praktijk besproken zoals de case Ondermijning & Fraude bij de gemeente Zaanstad en onze Risico Radar Ondermijning.
Heb je een vraag of opmerkingen over de vodcast van Wesley? Laat het ons dan weten via onderstaand formulier!
Wil je automatisch op de hoogte blijven van nieuwe edities van de Shintō Labs Masterclass? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via bovenstaand formulier en vink de ‘blog’ optie aan!
Andere masterclasses
Whitepapers
Productinformatie
Nieuws
Blogs
Webinars
Praktijkcases
Research

Deze maand zijn we gestart met een serie video’s waarin we onze kennis delen onder de noemer: Shintō Labs Masterclass. In iedere editie komt een expert aan het woord om over een specifiek onderwerp zijn of haar kennis te delen. We gaan in op verschillende vraagstukken rondom datagedreven werken en data analytics in de overheid. Onderwerpen kunnen variëren van innovatie methodiek, privacy, ethiek maar ook meer technische onderwerpen als netwerkanalyses en graph databases.
In deze editie vertelt CTO en Co-founder Eric van Esch over de rol van bias (onbewuste vooroordelen) in algoritmes, of zoals hij dat liever noemt: algoritmische systemen, en wat je daar tegen kunt doen. Naast theoretische kennis worden ook voorbeelden uit onze praktijk besproken zoals de Milieu Navigator en onze Risico Radar Ondermijning.
Heb je een vraag of opmerkingen over de vodcast van Eric? Laat het ons dan weten via onderstaand formulier!
Wil je automatisch op de hoogte blijven van nieuwe edities van de Shintō Labs Masterclass? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via bovenstaand formulier en vink de ‘blog’ optie aan!
Andere masterclasses
Blogs