
CSI: Crime Script Investigation – Netwerkanalyse met hulp van G-CORE
Ik was er helemaal klaar voor. Het vooronderzoek was gedaan en in mijn hoofd zat goed en duidelijk wat ik over zes maanden van toen, in augustus, zou presenteren om mijn ingenieur-titel te bemachtigen ter afronding van mijn afstudeeronderzoek bij Shintō Labs en mijn studie Data Science aan de TU/e. Enfin, we zijn nu 3 maanden verder, en in mijn hoofd is een hoop veranderd over wat ik over drie maanden van nu (nog steeds in augustus, dat is niet veranderd) zal gaan presenteren om mijn ingenieur-titel te bemachtigen. Een kleine tijd terug ben ik naar Den Haag afgereisd, om op uitnodiging van het Nederlands Forensisch Instituut op een maandelijks colloquium te presenteren over mijn onderzoek dusver. Een mooi moment om een blog te schrijven over deze ervaring, en daarmee ook over de huidige status van het onderzoek. Tijd voor een update!
Een mede-student van me, Frans, die bij het Nederlands Forensisch Instituut – NFI – zijn stage in mei begint, was ook mee om zijn vooronderzoek te presenteren en stond als eerste op het programma. Zijn afstudeeronderzoek zal voornamelijk gaan over het onderzoeken van het temporale aspect van criminele netwerken. Aangezien criminele netwerken continu veranderen, is een temporaal aspect in het netwerk van significant belang. Bij huidig onderzoek in netwerken wordt dit aspect vaak genegeerd; er wordt als het ware een snapshot van het netwerk onderzocht. Dit betekent dat onderzoek in deze netwerken mogelijk niet meer relevant is. In mijn eigen thesis staat bij de laatste hoofdstukken “Threats to validity” en “Future Research” de aantekening dat het temporale aspect mist, en ook in literatuur die ik tot dusver heb gelezen wordt gepleit voor een mogelijkheid om netwerken “live” te onderzoeken. Interessant werk dus, en heel veel betrekking op mijn eigen project.
CSI: Crime Script Investigation
Na de presentatie van Frans was het mijn beurt. In deze blog zal ik een uiteenzetting geven van mijn presentatie, en daarmee dus ook een update van mijn onderzoek. Mijn standaardtitel en ondertitel zijn inmiddels “CSI: Crime Script Investigation – Using graph databases to fight crime”. Dit was al zo tijdens het onderzoek, en dit is zo gebleven. De vraag die ik wil beantwoorden is dan ook niet veranderd; kan ik als ik een samenleving weergeef in een graaf doormiddel van slimme queries uitvoeren een crimineel netwerk eruit distilleren? De queries schrijf ik aan de hand van een crime script. Een crime script is een recept of een blauwdruk van hoe een misdaad werkt, het laat zien wat er moet gebeuren door wie, wat hier voor nodig is en waar dit moet gebeuren op welk moment. Het laat de gehele situatie zien van de misdaad, ofwel de gehele modus operandi. In literatuur wordt dit daarom ook een Situational Crime Prevention Approach genoemd. Crime scripts zijn opgebouwd in scenes, en in elke scene zit een set aan rollen die nodig is om de scene te voltooien. Dit is zeer vergelijkbaar met een script in het theater.
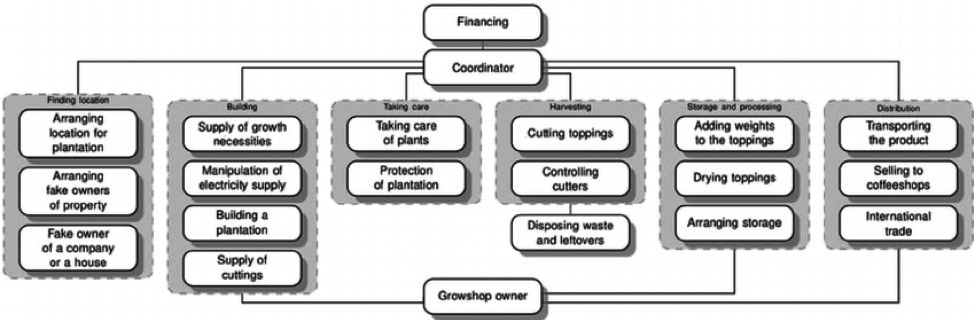
Figuur 1 – Cannabis-handel netwerk (Duijn, P. A. C. (2016). Detecting and disrupting criminal networks (Doctoral dissertation, PhD thesis.).
Het crime script is ook nog heel flexibel. Aangezien een crime script op meerdere manieren kan worden uitgevoerd, is dit een handige eigenschap. Morselli en Roy beschrijven in hun onderzoek naar criminele netwerken die auto’s stelen en de onderdelen doorverkopen dat de verkoop vaak naar het buitenland gebeurd. Ze beschrijven hoe de netwerken de auto-onderdelen laten verdwijnen in verschillende landen; Rusland, Egypte, Canada, Italië, etc. Elk zo’n optie heet een facet, en elke rol in een crime script kan meerdere facetten hebben. Hoe meer facetten, hoe moeilijker het is om het netwerk te breken. Bijvoorbeeld, als een crimineel netwerk bestaat uit 7 rollen en elke rol heeft 3 manieren om te voltooien (dus 3 facetten), dan zijn er in totaal 3^7 = 2187 verschillende permutaties waarin dit script kan worden voltooid.
Elk type misdaad zijn eigen crime script
Crime scripts kunnen op verschillende niveaus en voor verschillende soorten misdaad worden gemaakt. Elk type misdaad heeft zijn eigen crime script, en aangezien modus operandi verschillen kan er per crime script heel erg worden ingezoomd op een specifieke misdaad. Maar men kan ook de andere kant op en zo generaliseren, een crime script dat kan wordt gebruikt voor alle misdaden. Dit script is het universele script van Cornish, en is sinds 1994 al vaak gebruikt als begin punt voor het opstellen van een crime script.
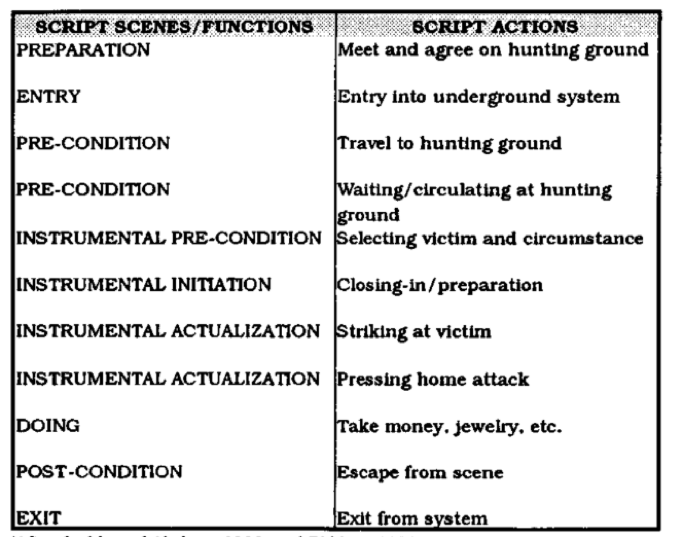
Figuur 2 – Universeel script van Cornish (Cornish, D. B. (1994). The procedural analysis of offending and its relevance for situational prevention. Crime prevention studies, 3, 151-196).
Crime scripts verschillen ook per methode. Een misdaad die op een individueel niveau afspeelt is meestal een stappenplan; de scenes zijn in volgorde geschreven van uitvoer. In zulke scripts kunnen rollen in meerdere scenes voorkomen, maar met net iets andere vereisten. Dit betekent dat er net iets andere queries moeten worden gebruikt voor dezelfde rol, en dat er dus verschillende mogelijke nodes uit het netwerk rollen die deze rol kunnen vervullen. Welke van deze nodes geschikt is kunnen we oplossen door de rollen in een conjunctive normal form te zetten. De oplossing van deze CNF zijn de nodes die echt interessant zijn.
Crime script en netwerken
Voor netwerken werken crime scripts weer net iets anders. Hierin zijn de scenes niet op volgorde. De scenes spelen zich simultaan af, omdat de hele operatie meerdere taken heeft die niet een voor een worden uitgevoerd maar tegelijkertijd om zo de operatie efficiënt te maken. Een scene is hier dus een deeloperatie; in een crime script voor drugsnetwerken zijn er dus bijvoorbeeld scenes voor de deeloperatie van productie, een voor verkoop, een voor management etc. Elke scene heeft nog steeds rollen gekoppeld, maar naast de wie, wat waar en wanneer in de standaard crime scripts zijn nu ook de connecties belangrijk zodat kan worden gezien hoe dit netwerk wordt gevormd. De topologie wordt is impliciet opgenomen in het script.
Tijdens mijn vooronderzoek wilde ik me concentreren op crime scripts in het algemeen. Echter, aan de hand van verder onderzoek en feedback heb ik besloten me voornamelijk te focussen op netwerk crime scripts. Deze zijn interessanter, en misdaden op individueel niveau worden weliswaar vaak met meerdere personen uitgevoerd, maar hiervan is een netwerk nog steeds niet echt sprake.
Crime scripts zijn een mooi uitgangspunt om dus queries op te stellen. Maar waarop worden de queries überhaupt op losgelaten? We beginnen met een graaf die een deel van de maatschappij toont. Dit kan bijvoorbeeld, in het straatje van Shintō Labs, een graaf van een gemeente zijn. Het kan ook een graaf zijn die uit is gekomen na aanleiding van uitgebreid politieonderzoek. In mijn vooronderzoek had ik beredeneerd dat ik, omdat ik de queries declaratief wilde hebben, ik deze graaf in het property graph model zou zetten en met zou werken. Een property graph is een graaf waarin de nodes en de edges die de nodes verbinden labels en property key-value pairs hebben. Dus een node kan als label Persoon hebben, en als properties leeftijd en geslacht, met een geassocieerde waarde. Cypher is de taal waarmee je deze grafen kan queryen. Hiermee kon je al interessante patronen herkennen in de graaf.
G-CORE: een nieuwe generatie netwerk analyse
Echter, een heel nieuw netwerk opbouwen vanuit het originele netwerk dat een crimineel netwerk representeert , dat gaat niet met Cypher. Tijdens het vooronderzoek werd door mijn begeleider vanuit de TU/e G-CORE aangeraden. Dit zou een oplossing kunnen bieden voor dit probleem, en dit heb ik dus onderzocht. G-CORE is een Graph Query Language (GQL) die werkt volgens het “Graph In, Graph Out” principe. Met als input een graaf, geven de queries dus een nieuwe graaf terug, en dat is inderdaad precies wat we nodig hebben. G-CORE werkt met het Path Property Graph model. Dit is hetzelfde als het property graph model, maar in plaats van alleen nodes en edges die labels en property key-value pairs kunnen hebben, kunnen paden in dit model dat ook. Daarmee kun je dus paden tussen verschillende dingen creëren en zoeken, om zo het gehele netwerk bij elkaar te krijgen. Ook stelt G-CORE je in staat om data te aggregeren, om zo de facetten van het crime script of de verschillende scenes in het netwerk te visualiseren.
Ter illustratie: G-CORE werkt met een “Graph In, Graph” out principe. De query die je gebruikt wordt dus losgelaten op een graaf, en er komt een nieuwe graaf uit die de query beantwoord. Een voorbeeld is te vinden in de afbeeldingen. In de eerste afbeelding is een kleine graaf te zien na aanleiding van de boeken en films van Harry Potter. De graaf toont gedeeltelijk wie een vloek heeft losgelaten op wie. Elke node is een tovenaar of heks, en de edge geeft aan wie een vloek heeft losgelaten op wie. Elke edge heeft een property key-value pair dat laat zien welke vloek er is gebruikt, de values zijn afgebeeld op de edge.
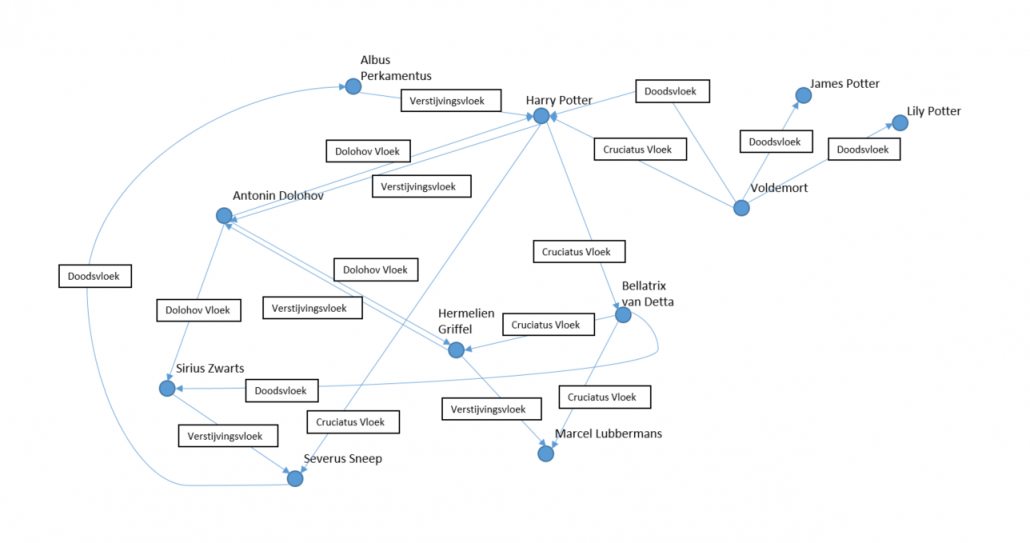
Figuur 3: G-CORE voorbeeld uitgewerkt in de wereld van Harry Potter
Door middel van G-CORE kunnen we een nieuw netwerk maken, dat alle vloeken als node gebruikt, alle tovenaars en heksen als node, en pijlen die laten zien hoe een tovenaar of heks in aanraking is geweest met de vloek. Een groene pijl betekent dat hij of zijn de vloek heeft gebruikt, een zwarte pijl betekent dat hij of zij slachtoffer is geweest van de vloek. Met dit nieuwe overzicht kunnen we dus in een opslag zien wie door de meeste vloeken is geraakt en wie de meeste vloeken kent, iets wat uit de eerste graaf niet direct via een query kon worden opgevraagd.
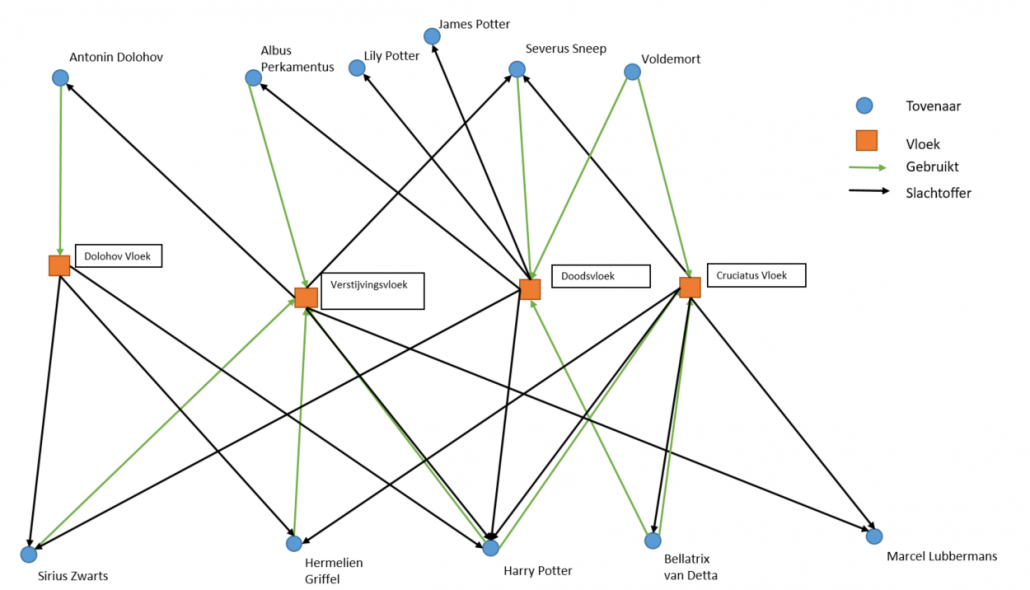
Figuur 4: Detaillering van de vloeken
Dit alles zou in een tool moeten komen, waarin een gebruiker een graaf en een crime script als input geeft, en op verschillende niveaus mogelijke criminele netwerken eruit vist, samen met enkele statistieken die heel handig zijn om dit netwerk snel te analyseren. Deze statistieken zijn eenvoudig via ingebouwde algoritmen met Cypher te verkrijgen. Ook krijgt de gebruiker een visualisatie te zien van het netwerk en een verdeling hoe de rollen in het netwerk zijn verdeeld. Het ontwikkelen van deze tool staat op een lager pitje op dit moment, daar de haalbaarheid van deze tool niet meer zo hoog is als aan het begin van het afstudeerproject. De connectie maken tussen alle verschillende mechanieken die de tool moet kunnen is zacht gezegd te hoog gegrepen om te voltooien in zes maanden, zeker als we bedenken dat G-CORE nog in de kinderschoenen staat en veel zaken nog niet geïmplementeerd zijn die wel nodig zijn voor deze toepassing. Deze gebreken in G-CORE oplossen zijn op het moment de grootste hindernis, en een groot deel van de bezigheden de laatste komende maanden. Voor nu test ik dit op een kleine graaf die ik zelf heb gemaakt met zelf verzonnen data, en een crime script dat lichtelijk is gebaseerd op het crime script over cannabis-netwerken van Duijn. De graaf heb ik gemaakt in Neo4j met Cypher. Echter, G-CORE kan helaas niet rechtreeks zijn graaf inlezen vanuit Cypher, dit moet eerst worden herschreven. Dit houdt in dat ik de afgelopen week alles heb gexporteerd naar een JSON-file, en met een Python script deze JSON file heb omgeschreven naar de bestanden die de G-CORE interpreter die de TU/e heeft gemaakt kan lezen. Dit had een paar pogingen nodig, maar inmiddels is mijn property graph omgezet naar een path property graph. De G-CORE queries die ik al heb gemaakt kunnen nu dus getest worden. Als alles werkt, zal de volgende stap zijn dit toe te passen op “echte” data, data vanuit gemeenten en openbare data, om te zien of daar interessante zaken uitgehaald kunnen worden. De komende maanden zal er op dat gebied dus data worden geworven en een crime script worden ontwikkeld. Qua tool wordt er waarschijnlijk een klein prototype gemaakt zodat er een algemeen beeld is van hoe de tool eruit kan zien en hoe hij gebruikt kan worden. In het vooronderzoek had ik daar al wat schetsen gemaakt, deze moeten lichtelijk veranderd worden en natuurlijk moet er een clickable prototype van worden gemaakt.
Dit sloot mijn presentatie bij het NFI. De aanwezigen waren onder de indruk, en gaven nuttige feedback. Zo waren ze er nog niet helemaal zeker van hoe precies ik het crime script kon toepassen; veel data die ik in mijn voorbeeld had gebruikt was niet zomaar aanwezig. Natuurlijk was mijn voorbeeld ook niet realistisch, maar gebruik ik het enkel om G-CORE queries mee te testen, maar het geeft wel aanzet tot denken dat in echte cases het crime script dus goed moet worden uitgedacht om kans van slagen te hebben. Ondanks dat men bij het NFI niet veel met graph technology doet, vonden ze de toepassing van G-CORE zeer veelbelovend. Het colloquium werd beëindigd door een presentatie van een vrouw die onderzoek doet in criminele organisaties voor de nationale politie. De precieze inhoud was vertrouwelijk, maar de conclusie was dat als men wetenschappelijk onderzoek hard wil maken in rapporten of de rechtbank, dat alle stappen moesten kloppen en duidelijk waren. Er mogen geen shortcuts gebruikt worden, want dan maken advocaten gehakt van je, vertelde ze. Deze boodschap heb ik ook ter harte genomen; de queries die ik had opgeschreven heb ik opgesplitst in delen, zodat bij elke stap duidelijk is wat er gebeurt en waarom.
Van uitwerken naar implementatie
We zitten op de helft, en er is al een hoop gedaan en veranderd. Waarschijnlijk gaat er nog wel wat meer veranderen. Het doel is echter nog steeds hetzelfde, en ik hoop dat in de blog die ik over drie maanden schrijf er ook het nieuws in staat dat ik ben afgestudeerd met dit onderzoek. Waar ik mij op ga richten is het uitwerken van deze concepten in Apache Spark met hulp van Scala. Dat gaan we vervolgens toetsen bij een van de gemeentes om het netwerk daar inzichtelijk te maken. Ondertussen zal ik kleine updates blijven geven over interessante gebeurtenissen tijdens mijn afstuderen.
Bronnen
– Cornish, D. B. (1994). The procedural analysis of offending and its relevance for situational prevention. Crime prevention studies, 3, 151-196. Bekijk PDF
– Duijn, P. A. C. (2016). Detecting and disrupting criminal networks (Doctoral dissertation, PhD thesis. Retrieved from https://dare. uva. nl/search). Bekijk PDF
– Morselli, C., & Roy, J. (2008). Brokerage qualifications in ringing operations. Criminology, 46(1), 71-98. Bron
– Angles, R., Arenas, M., Barceló, P., Boncz, P., Fletcher, G., Gutierrez, C., … & van Rest, O. (2018, May). G-CORE: A core for future graph query languages. In Proceedings of the 2018 International Conference on Management of Data (pp. 1421-1432). ACM. Bron
Relevante links
Whitepapers
- Whitepaper ‘Een datagedreven aanpak van ondermijnende criminaliteit’
- Whitepaper ‘Van maatschappelijke opgave naar datagedreven toepassing’
Nieuws
- Gemeente Hollands Kroon kiest voor Apollo platform
- Lancering Apollo: data & analyse platform voor de aanpak van ondermijning
- Workshop ‘Je gaat het pas zien als je het door hebt’ op Congres Ondermijning & Georganiseerde Criminaliteit
- Applicatie Ondermijning uitgelicht als dataproject
- Design Sprint Horeca & Ondermijning met gemeente Purmerend
Blogs
- Podcast: een datagedreven aanpak van ondermijning in de gemeente Diemen
- Een datagedreven aanpak van ondermijning bij het misbruik van vastgoed
- Kwetsbare personen in de samenleving: meekijken in een Design Sprint
- Van radar tot sonar: signaleren van ondermijnende criminaliteit met data science
- Ondermijning in 2021: naar weerbare wijken en een structurele aanpak
- Dé 3 thema’s voor ondermijning in 2020
- Een crimineel samenwerkingsverband in 10 minuten
- Van ruwe data naar bruikbare intelligence in vier stappen
- Naar een datagestuurd veiligheidsbeleid
- 5 redenen waarom je als gemeente datagedreven werken samen moet doen
Webinars
- Webinar Risico Radar Ondermijning met RIEC Rotterdam en Bureau Beke
- Webinar Ondermijning en fraude met de gemeente Zaanstad
- Webinar Monitor Vakantieparken met Bureau Beke
- Webinar Gebiedsgericht werken aan leefbaarheid en sociale veerkracht in de buurt
- Masterclass: Opsporen van verdachte netwerken in gemeentelijke data
Praktijkcases
- Aanpak Ondermijnende Criminaliteit: Vastgoedfraude
- Aanpak van Ondermijnende Criminaliteit: Buitengebied
- Aanpak Ondermijnende Criminaliteit: Kwetsbare branches en bedrijven
- Aanpak Ondermijnende Criminaliteit: Woon- en adresfraude
- Aanpak van illegaal kamerverhuur en woningsplitsing
- Monitor Vitale Vakantieparken: Veiligheid en leefbaarheid op vakantieparken
- Datagedreven milieutoezicht & -handhaving
- Leefbaarheid en veerkracht van de buurt
Productinformatie
Research









