
Onderzoek: hoe geodemografie kan helpen om data ‘eerlijker’ weer te geven
De afgelopen elf maanden ben ik ondergedompeld in de wereld van data. Via de ’track’ Data Science als onderdeel van Information Studies aan de UvA kwam ik in contact met allerlei toffe algoritmes en maakte ik kennis met de problematiek achter de technische hoogstandjes. Een van deze problemen was gericht op ondermijning in Amsterdam en bij het zoeken naar vergelijkbare projecten kom je dan al snel uit bij Shintō Labs.
Met zwetende handjes heb ik een voorzichtig mailtje gestuurd naar het ‘Shinteam’ of ik ‘heel misschien’ en ‘alleen als het uitkomt’ langs mocht komen om de mogelijkheid tot een afstudeerstage te bespreken. Wat ik niet verwachtte is dat de daaropvolgende uitnodiging zo relaxed en soepel verliep dat ik direct verkocht was. Daar wil ik graag mijn thesis schrijven! Inmiddels zijn we vijf maanden verder en is het papiertje op zak en ik kan wel stellen dat ik geen spijt heb van deze keuze. Natuurlijk was het hard buffelen, maar het waren ook enorm leerzame maanden waarbij ik vanaf dag één door het team ben opgenomen. Ook nam ik deel aan de Design Sprint met het RIEC Rotterdam en Bureau Beke op het thema Risico Radar Ondermijning, waarbij we op basis van open bronnen de mogelijke hotspots inzichtelijk maken. In deze sprint kon ik mijn onderzoek mooi toepassen.
In deze blog beschrijf ik mijn onderzoeksopzet en de eerste resultaten. In de onderstaande video kun je ook de presentatie zelf zien.
De casus
De core business van Shintō Labs bestaat uit het maken van datagedreven applicaties voor overheidsinstellingen. Vaak bevat een applicatie een dashboard met een kaart waarop dan data is geplot. In verband met privacy wordt die data vaak gepresenteerd per postcode, buurt of wijk (en dus niet per huis of gebouw).
De keuze voor het type gebiedsindeling kan echter een vertekenend beeld geven van de werkelijkheid. In figuur 1 zie je bijvoorbeeld drie representaties van exact dezelfde data, maar met verschillende gebiedsindelingen. Dit probleem staat in de boeken bekend als MAUP – The Modifiable Area Unit Problem. Dit fenomeen doet zich ook voor wanneer we data presenteren per postcode, buurt of wijk: hoe meer variatie er in zo een gebied plaats vindt, hoe meer informatie wordt weggegooid wanneer de data wordt geaggregeerd.
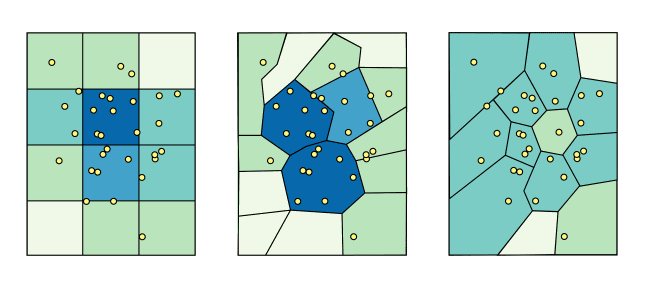
Figuur 1 Voorbeeld van ‘The Modifiable Area Unit Problem’
Een manier om dit probleem aan te pakken is door gebiedsindelingen datagestuurd te maken. Als we de bestaande wijken/buurten loslaten en kijken naar de achterliggende data, dan kunnen we gebieden creëren die de mensen in het gebied zo veel mogelijk vertegenwoordigen. Dit doen we door middel van geodemografie; ‘The study of people by where they live’ (Harris, 2005).
Geodemografie
Zoals de naam al prijs geeft is dit vakgebied een combinatie van geografie en demografie, waarmee de data ook direct complex wordt. In geodemografie word er gezocht naar betekenisvolle bundels om de mensen in een gebied te kunnen beschrijven. Deze bundels worden in de literatuur ook wel micro-communes of urban neighbourhoods genoemd. Door middel van algoritmen worden mensen ingedeeld in clusters, die vervolgens worden geplot op een kaart. In principe volgt iedere geodemografische clustering ruwweg hetzelfde proces van datapreparatie, algoritmeselectie en parameterselectie, maar het probleem ontstaat bij de evaluatie. Want wat zijn betekenisvolle clusters? Dat is een bijna filosofische vraag, die niet zomaar beantwoord kan worden. Voor de fijnproevers raad ik het paper van ‘What are true clusters’ aan van Christian Hennig.

Figuur 2. Voorbeeld van een geodemografische clustering van Eindhoven. Bron: CBS
Geodemografische cluster-evaluatie
In tegenstelling tot standaard ‘gesuperviseerde methoden’ is het valideren van een geodemografische clustering een schemerig gebied tussen kunst en wetenschap, het kwantitatieve en het kwalitatieve, objectiviteit en subjectiviteit (Harris, 2005). Zoals mijn docent het noemt, is cluster-evaluatie in feite een vorm van zwarte magie.
Binnen de geodemografie is er wel een idee van enkele eigenschappen die een clustering betekenisvol maken, waarvan de belangrijkste eigenschap is, dat de clustering aansluit bij het doel en de context van het clusterprobleem. Om dat doel meetbaar te maken gebruiken we interne en/of externe criteria die helpen bij het maken van de keuze van het algoritme en de parameter instellingen.
De externe criteria bestaan soms uit vergelijkingen met referentieclassificaties of een zogenoemde ground truth. Veel vaker worden subjectieve criteria opgelegd met behulp van experts of de eindgebruikers. De interne evaluatie van een clustering bestaat uit het meten van een bepaalde regel die de data beschrijft zoals ‘hoe compact zijn de clusters?’ of ‘wat is de ratio tussen de gemiddelde inter en intra clusterafstand?’. Hoewel deze regels objectief zijn, is het wel de vraag hoeveel waarde je moet hechten aan de resulterende waarden en hebben deze regels zeker niet altijd toegevoegd nut. Over het algemeen wordt interne evaluatie daarom vooral gebruikt om het cluster proces te sturen en niet te leiden (Alexiou, 2017).
De interne evaluatie regels hebben nog een extra uitdaging, want deze methoden zijn over het algemeen niet aangepast aan geodemografische clustering. De meest gebruikelijke metrieken (zoals de Within-cluster sum-of-squares en de Silhouette index) worden alleen toegepast op de demografische data en niet op de geografische data. Dit terwijl ´echte’ microcommunes samenhang lijken te vertonen in zowel de geografische als demografische ruimte (Wolf et al., 2019).
De kern
In mijn onderzoek heb ik geprobeerd een regel op te stellen die speciaal geadapteerd is voor geodemografische data. Deze regel is gebaseerd op de Silhouette score, maar met een speciale functie die afstand kwantificeert als combinatie van geo- en demografische data. Er zitten aan een dergelijke functie nog flink wat haken en ogen: hoe verhoudt bijvoorbeeld geografie zich tot demografie? Uiteindelijk hebben we als ‘proof of concept’ de aanpak van Wolf et al. overgenomen (inmiddels liep de onderzoeksperiode al tegen het einde).
Uit een kleinschalig experiment komt naar voren dat de geodemografische score wel degelijk wat interessante patronen vertoont. Zeker ten opzichte van de conventionele (non-geografische) Silhouette score lijkt de nieuwe regel een stuk minder triviale patronen weer te geven. Dit bleek ook uit de validatie (feedback van gebruikers) van het prototype van de Risico Radar Ondermijning zoals ik die heb gerealiseerd voor het RIEC Rotterdam.
Lessons learned
Het voorgaande stuk ging vrij snel de diepte in en eindigt tamelijk theoretisch. Maar wat zijn nu de take home wijsheden die we tijdens het onderzoek zijn tegengekomen?
Een van de belangrijkste redenen om interne evaluatie regels te zoeken is om subjectiviteit in geodemografie te verminderen. We willen graag goed gefundeerde keuzes maken tijdens het clusterproces en idealiter is geodemografie zo transparant mogelijk. In de praktijk blijven de objectieve evaluatie technieken slechts een onderdeel van het clusterproces, waar de keuzes voor het algoritme en de parameter instellingen uiteindelijk worden gemaakt door mensen. Het maken van een geodemografische clustering is niet moeilijk, maar een goede geodemografische clustering maken is een flinke uitdaging, die ook afhangt van de context.
Hoe nu verder?
Tot nu toe hebben we een paar keer genoemd dat interne validatie regels vooral ‘betekenis’ krijgen in het kader van een context en met een expert/gebruiker om de context te interpreteren. Hoewel mijn thesis vooral de theorie van geodemografische evaluatie beslaat, zijn we natuurlijk erg benieuwd of de interne regels ook echt hulp bieden tijdens het clusteren. Daarom ben ik met het Shintō Labs team begonnen aan een interactieve module waarmee je je eigen (geodemografische) data kan clusteren. De module geeft adviezen op basis van de interne evaluatie regels, maar uiteindelijk is het aan de gebruiker om de waarde van de clustering in te schatten. Voor nu blijft het dashboard bij een prototype, maar mocht je interesse hebben in deze applicatie, neem dan contact op met het Shintō Labs.

Figuur 3. Prototype van het dashboard
Referenties
- Alexiou, A. (2017). Putting ’Geo’ into Geodemographics: evaluating the performance of national classification systems within regional contexts. PhD thesis, University of Liverpool.
- Harris, R., Sleight, P., and Webber, R. Geodemographics, GIS and Neighbourhood Targeting. Wiley, London, UK, 2005
- Hennig, C. (2015). What are the true clusters?. Pattern Recognition Letters, 64, 53-62.
- Wolf, L., Knaap, E., and Rey, S. J. (2019). Geosilhouettes: geographical measures of cluster fit.
Relevante links
Whitepapers
- Whitepaper ‘Een datagedreven aanpak van ondermijnende criminaliteit’
- Whitepaper ‘Van maatschappelijke opgave naar datagedreven toepassing’
Nieuws
- Gemeente Hollands Kroon kiest voor Apollo platform
- Lancering Apollo: data & analyse platform voor de aanpak van ondermijning
- Workshop ‘Je gaat het pas zien als je het door hebt’ op Congres Ondermijning & Georganiseerde Criminaliteit
- Applicatie Ondermijning uitgelicht als dataproject
- Design Sprint Horeca & Ondermijning met gemeente Purmerend
Blogs
- Podcast: een datagedreven aanpak van ondermijning in de gemeente Diemen
- Een datagedreven aanpak van ondermijning bij het misbruik van vastgoed
- Kwetsbare personen in de samenleving: meekijken in een Design Sprint
- Van radar tot sonar: signaleren van ondermijnende criminaliteit met data science
- Ondermijning in 2021: naar weerbare wijken en een structurele aanpak
- Dé 3 thema’s voor ondermijning in 2020
- Een crimineel samenwerkingsverband in 10 minuten
- Van ruwe data naar bruikbare intelligence in vier stappen
- Naar een datagestuurd veiligheidsbeleid
- 5 redenen waarom je als gemeente datagedreven werken samen moet doen
Webinars
- Webinar Risico Radar Ondermijning met RIEC Rotterdam en Bureau Beke
- Webinar Ondermijning en fraude met de gemeente Zaanstad
- Webinar Monitor Vakantieparken met Bureau Beke
- Webinar Gebiedsgericht werken aan leefbaarheid en sociale veerkracht in de buurt
- Masterclass: Opsporen van verdachte netwerken in gemeentelijke data
Praktijkcases
- Aanpak Ondermijnende Criminaliteit: Vastgoedfraude
- Aanpak van Ondermijnende Criminaliteit: Buitengebied
- Aanpak Ondermijnende Criminaliteit: Kwetsbare branches en bedrijven
- Aanpak Ondermijnende Criminaliteit: Woon- en adresfraude
- Aanpak van illegaal kamerverhuur en woningsplitsing
- Monitor Vitale Vakantieparken: Veiligheid en leefbaarheid op vakantieparken
- Datagedreven milieutoezicht & -handhaving
- Leefbaarheid en veerkracht van de buurt
Productinformatie
Research









