Alweer een tijdje terug zijn we gestart met een serie video’s waarin we onze kennis delen onder de noemer: Shintō Labs Masterclass. In iedere editie komt een expert aan het woord om over een specifiek onderwerp zijn of haar kennis te delen. We gaan in op verschillende vraagstukken rondom datagedreven werken en data analytics in de overheid. Onderwerpen kunnen variëren van innovatie methodiek, privacy, ethiek maar ook meer technische onderwerpen als machine learning, text analytics en graph databases.
Predictive Analytics: voorspellen van vertraging in de woningbouw
In deze editie wordt master student Aron van Lith geinterviewd door data scientist Wesley Brants over over het voorspellen van vertraging in de woningbouw. Aan bod komen onderwerpen zoals verschillende voorspellingsmodellen, gebruikte datasets en de mogelijke praktische toepassing in de Woningbouw Monitor.
Heb je een vraag of opmerkingen over de masterclass van Aron en Wesley? Laat het ons dan weten via onderstaand formulier!
Abonneren
Wil je automatisch op de hoogte blijven van nieuwe edities van de Shintō Labs Masterclass? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via bovenstaand formulier en vink de ‘blog’ optie aan!
https://www.shintolabs.nl/wp-content/uploads/2023/07/Masterclass-predictive-analytics-voorspellen-van-vertraging-in-de-woningbouw-website.png16092869Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2023-07-14 15:45:232023-07-14 19:07:43Masterclass – Predictive Analytics: voorspellen van vertraging in de Woningbouw
In mijn eerdere blog schreef ik over het Open Development Programma waarmee we samen met overheidsorganisaties bouwen aan oplossingen voor maatschappelijke opgaven. Eén van de onderdelen die op deze manier tot stand is gekomen, is onze implementatie van het Model Privacy Protocol ter ondersteuning van het beoordelen van ondermijningssignalen in ons Apollo Platform. In deze blog wil ik een toelichting geven op hoe dit uitgewerkt is en hoe gemeentes hier gebruik van kunnen maken.
Onze implementatie van het Model Privacy Protocol in Apollo biedt enkele voordelen nl.:
Voorkomen van bovenmatig gebruik van gegevens.
Inzichtelijk maken met welk doel en op welke wijze gegevens worden verwerkt.
Zicht krijgen op ondermijning binnen de grenzen van de gemeente.
Kaders stellen voor waarborgen van rechtmatigheid.
Verantwoording af kunnen leggen over de werkwijze.
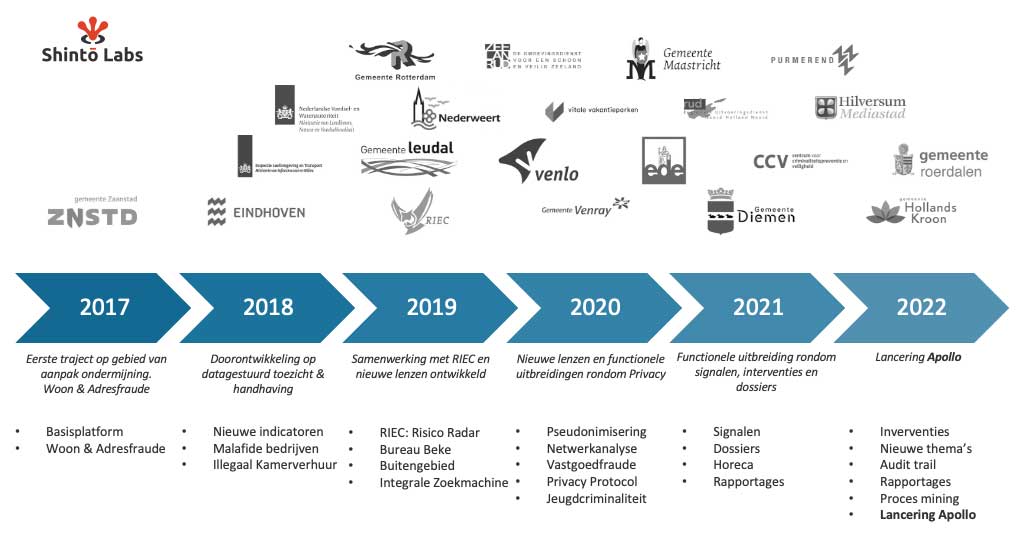
Maar voor dat ik in ga op de inhoudelijke functionaliteiten van het Model Privacy Protocol in Apollo, is het goed om een begrip te hebben hoe dit tot stand is gekomen en waarom dit überhaupt een plek moet krijgen in Apollo. Om dat pad te illustreren neem ik jullie even mee naar het jaar 2017, toen wij in contact kwamen met Tom Pots van de gemeente Zaanstad en ondermijning een opkomend thema was.
Een aanpak van ondermijnende criminaliteit – een eerste verschijningsvorm: woon- en adresfraude
De gemeente Zaanstad wilde een datagedreven aanpak van ondermijnende criminaliteit, maar was zoekende hoe ze dat moest vormgeven. Wij hebben toen met de gemeente Zaanstad een Design Sprint gedaan om een eerste versie van een datagedreven applicatie voor de aanpak van ondermijnende criminaliteit te ontwerpen. De focus van het prototype lag bij woon- en adresfraude. Dit prototype is vertaald naar een applicatie en inmiddels in meerdere iteraties doorontwikkeld tot Apollo, ons data & analyse platform voor de aanpak van ondermijning.
Van eerste applicatie ondermijning met Zaanstad naar Apollo
Van verschijningsvormen naar lenzen
In onze zoektocht met gemeentes over een datagedreven aanpak van ondermijning, bleken er veel andere verschijningsvormen te zijn van ondermijnende criminaliteit. De basis van de ‘Zaanse ondermijningsapplicatie’ bleek echter ook geschikt voor de andere fenomenen: het slim combineren en analyseren van data om risicovolle locaties te vinden. Via het Open Development Programma zijn er op deze manier verschillende lenzen ontwikkeld om de verschijningsvormen te kunnen analyseren, waaronder het buitengebied, ondermijning in de horeca, vastgoedfraude, industrieterreinen, uitbuiting en mensenhandel, milieu, netwerkstructuren in risicobranches, de Risico Radar Ondermijning en drugslocaties. Deze lenzen zijn beschikbaar binnen ons Apollo platform voor een datagedreven aanpak van ondermijnende criminaliteit.
Lenzen combineren met signalen
Toen we met de gemeente Diemen aan de slag gingen met het fundament dat in Zaanstad is gelegd, bleek dat zij een aanvullende wens hadden. Kunnen we niet ook de signalen die we binnen krijgen op een gestructureerde manier bijhouden en analyseren in de applicatie? De meeste gemeentes krijgen vele signalen binnen die kunnen duiden op een vorm van ondermijnende criminaliteit. Voor het duiden en analyseren van deze signalen is toegang tot data nodig. Deze tweede vorm van analyse -een signaal-gedreven aanpak op basis van signalen en meldingen – biedt extra inzichten en versterkt het beeld wat er binnen de gemeente speelt. De vraag is echter, wat kan je met die kennis? Immers, de gemeente is geen politie.
Een bestuurlijke aanpak van ondermijning
Kenmerkend voor de bestuurlijke aanpak is dat het zich niet zozeer richt op de kernactiviteiten van georganiseerde criminaliteit, maar juist op de cruciale ondersteunende activiteiten. De maatregelen richten zich niet op personen, maar op situaties en gelegenheidsstructuren die georganiseerde criminaliteit faciliteren. De onderwereld is namelijk afhankelijk van legale logistieke voorzieningen, infrastructuren, technische expertise en van de overheid als vergunningverlener. Daarmee heeft het openbaar bestuur een belangrijk wapen in handen in de aanpak van ondermijnende criminaliteit. (Handboek bestuurlijke aanpak; CCV 2010; ISBN 978 90 77845 37 0.).
Het bestuurlijk instrumentarium kent echter wel degelijk een aantal bestuurlijke interventies, zoals het opleggen van sancties op grond van de Algemene wet bestuursrecht (Awb) en diverse andere wetten en activiteiten voor het al dan niet verstrekken of intrekken van vergunningen (de Algemene Plaatselijke Verordening, Drank- en Horecawet, Opium-wetgeving en het bestemmingsplan). En bij de toepassing van de Wet bevordering integriteitsbeoordelingen door het openbaar bestuur (Wet Bibob).
De vraag die de beleidsmedewerkers veiligheid keer op keer kregen van juristen was: op basis van welke grond mag je iets doen met die signalen? En daar komt het Model Privacy Protocol om de hoek kijken. Immers, bij de bestuurlijke aanpak van ondermijnende criminaliteit, is een juiste afweging nodig om te bepalen of er wel sprake is van ondermijnende criminaliteit en of het wel binnen het bestuursrecht valt. Kortom, mag de gemeente hier wel op handelen? En zo ja, op basis van welke wetgeving?
Het Model Privacy Protocol
Het Model Privacy Protocol is in 2020 door de Rijksoverheid verspreid met als doel gemeenten te ondersteunen bij de wijze waarop zij informatie binnen gemeentes mogen uitwisselen voor de aanpak van ondermijning. Het biedt dan ook een basis voor een eigen privacy protocol voor de binnengemeentelijke gegevensuitwisseling en kan als handleiding dienen ten behoeve van de bestrijding van ondermijning. Zoals elk model moet ook dit model aangepast worden naar lokale omstandigheden, maar het geeft een goed uitgangspunt en is ons door meerdere juristen geadviseerd als een solide basis.
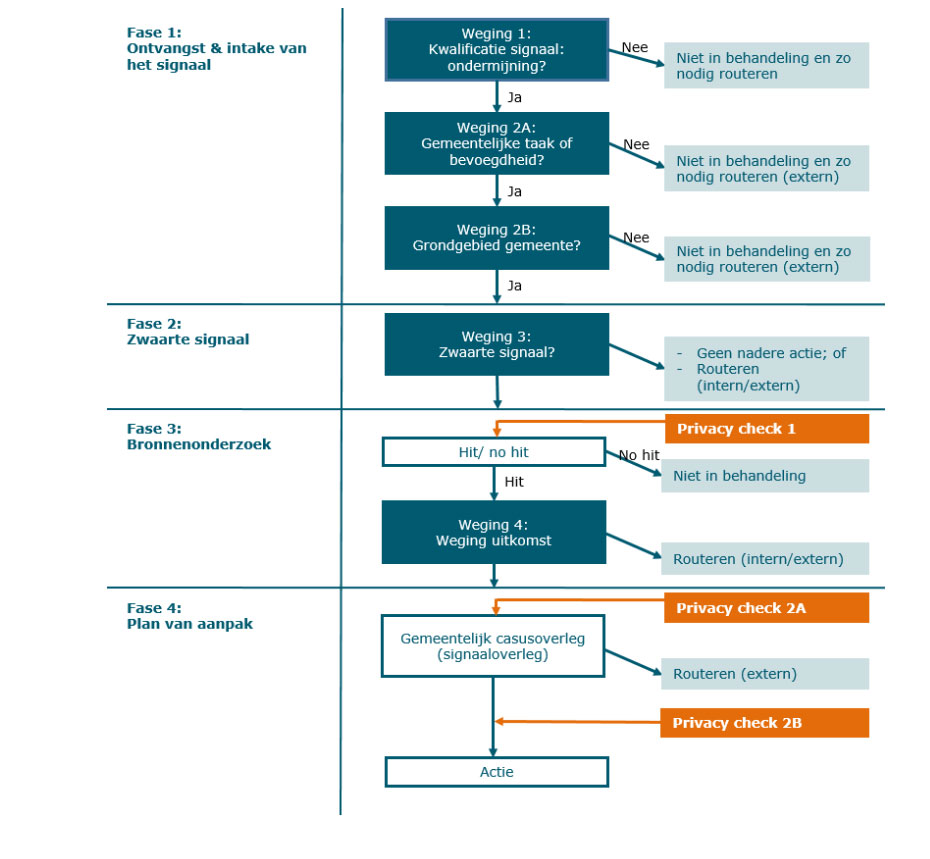
Het Model Privacy Protocol geeft een proces weer met verschillende fases, waarin signalen beoordeeld kunnen worden. Die verschillende weegpunten moeten helpen bij het beantwoorden van vragen zoals:
Kwalificeert het signaal wel als ondermijning?
Is het wel de gemeentelijke taak of bevoegdheid?
Valt het wel op het grondgebied van de gemeente?
Zie hieronder de schematische weergave van het proces (rechtstreeks ontleend uit het document van het Model Privacy Protocol). Het gaat te ver voor deze blog om het proces uit te schrijven – daarvoor kunt u het Model Privacy Protocol zelf raadplegen op de site van de Rijksoverheid.
Apollo implementatie van het Model Privacy Protocol
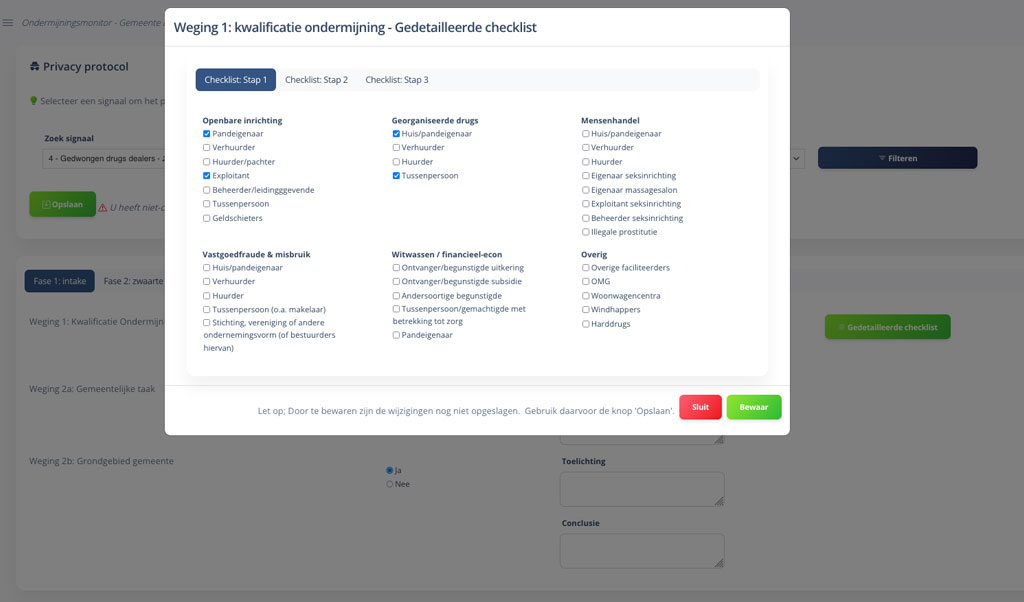
In Apollo wordt het proces van het Model Privacy Protocol volledig ondersteund, maar op een non-restrictieve manier. Dat wil zeggen: het biedt alle fases en stappen uit het Model Privacy Protocol, ondersteuning met inhoudelijke kwalificatie en alle mogelijkheid om toelichting te geven bij ieder weging, maar de mate waarin het afgedwongen wordt is flexibel. Zo kan het gebruikt wordt als een grote checklist met toelichting velden zodat de beleidsmedewerker alle zaken kan noteren en de juiste afweging kan maken, maar biedt het ook de ruimte om dat in stappen te doen.
Gedetailleerde checklist van Apollo
De Apollo implementatie biedt samengevat de volgende functionaliteiten:
Juridische basis voor het beoordelen van signalen: door meerdere Privacy Officers als akkoord bestempeld als onderbouwing van gebruik gegevens en beoordeling signalen.
Voor beleidsmedewerkers biedt het een eenvoudige maar potentieel uitgebreide checklist om signalen te beoordelen volgens het Model Privacy Protocol.
Het raamwerk is gebaseerd op het Model Privacy Protocol (4 fases, verschillende weegmomenten en privacy checks), maar flexibel in te richten om aan uw lokale wensen en eisen te voldoen.
Eenvoudig signalen zoeken en beoordelen.
Rapportages over de signalen en beoordelingen om inzicht te krijgen.
Hopelijk geeft dit enig inzicht in hoe het Model Privacy Protocol een plek heeft gekregen in Apollo en geeft het een goed beeld van de wijze waarop wij je kunnen helpen bij de aanpak van ondermijnende criminaliteit.
Meer informatie of een demo?
Wil je meer weten over Apollo of zelfs een keer een demonstratie? Check dan de productpagina over Apollo.
https://www.shintolabs.nl/wp-content/uploads/2022/11/blog-hoe-kun-je-privacy-waarborgen-bij-een-datagedreven-aanpak-van-ondermijning-scaled.jpg17072560Jurriaan Souerhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngJurriaan Souer2022-11-01 09:00:502022-11-24 12:12:47Hoe kun je privacy waarborgen bij een datagedreven aanpak van ondermijning?
De gemeente Hollands Kroon kiest voor het Apolloplatform van Shintō Labs. De gemeente wil een integrale aanpak op fenomenen, branches en locaties ontwikkelen waar sprake is van ondermijning dan wel gebieden die hiervoor kwetsbaar zijn. Apollogaat de beleidsmedewerkers openbare orde & veiligheid van de gemeente ondersteunen in het verwerken van signalen, het doen van vervolgonderzoek en het plannen van acties en interventies. De gebruikers van Apollo worden bij de analyse ondersteund met een privacy protocol om signalen nader te analyseren conform de huidige wet- en regelgeving.
De gemeente Hollands Kroon kwam in contact met Shintō Labs tijdens een kennissessie met gemeentes in de regio waarin de mogelijkheden werden besproken van een datagedreven aanpak van ondermijning in het buitengebied. Op basis van een demonstratie van de mogelijkheden is de gemeente verder in gesprek gegaan. In die periode was Shintō Labs ook al bezig om de resultaten van de vele ontwerp- en ontwikkeltrajecten in het veiligheidsdomein bij elkaar te brengen in het nieuwe Apollo platform. Voor de gemeente Hollands Kroon een mooi moment om een volgende stap te zetten.
Microsoft Azure cloud
Hollands Kroon geniet bekendheid als innovatieve gemeente. In 2016 besloot zij als één van de eerste gemeenten om haar werkomgeving, applicaties en ICT-infrastructuur te migreren naar de Azure cloud van Microsoft. Apollo draait eveneens op Microsoft Azure en beschikt over de mogelijkheid om data gepseudonimiseerd te verwerken. Dit betekent dat data versleuteld wordt opgeslagen in Apollo en dat deze alleen binnen de eigen cloud omgeving van de gemeente na een overwogen beslissing kan worden ‘ontsleuteld’. Dit biedt voordelen in het waarborgen van de privacy en de informatieveiligheid bij het verwerken en analyseren van de gegevens.
Onderdeel van een community
Door gebruik te maken van Apollo wordt de gemeente Hollands Kroon onderdeel van een community van overheidsorganisaties die samen werken en ontwikkelen aan een datagedreven aanpak van ondermijning. Apollo kent namelijk het Open Development Programma. Het achterliggende principe van dit programma is dat iedere organisatie of individu kan bijdragen en daar vervolgens van kan meeprofiteren. Meer concreet: als gemeente ‘A’ iets ontwikkeld heeft, kan gemeente ‘B’ daar gebruik van maken en andersom, zonder dat daar extra kosten mee gemoeid zijn. Zo ontwikkelen we samen aan een mooier en veiliger Nederland.
Meer informatie of een demo?
Wil je meer weten over Apollo of zelfs een keer een demonstratie? Check dan de productpagina over Apollo.
https://www.shintolabs.nl/wp-content/uploads/2022/10/Hollands-Kroon-kiest-Apollo-scaled.jpg17072560Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2022-10-13 11:02:082022-10-13 13:46:51Gemeente Hollands Kroon kiest voor het Apollo platform
Hoe staan de vakantieparken in uw gemeente ervoor? Hoe is de kwaliteit? Welke trends en ontwikkelingen zijn zichtbaar? En heeft de aanpak het gewenste effect? Om hierover optimale informatie te krijgen is er nu de Monitor Vitale Vakantieparken: een uniek, toegankelijk, online instrument, ontwikkeld door het programma Vitale Vakantieparken, Bureau Beke en Shintō Labs.
De Monitor is beschikbaar voor alle gemeenten en andere overheden in Nederland. Ontwikkelkosten hoeven dus niet opnieuw gemaakt te worden. De Monitor Vitale Vakantieparken is in Nederland de enige in zijn soort.
Deze video laat u zien hoe de Monitor Vitale Vakantieparken werkt, hoe deze is ingericht en vooral hoe u de monitor kunt benutten om te komen tot het juiste beleid en de beste aanpak.
Heb je belangstelling voor de Monitor Vitale Vakantieparken en wil je deze mogelijk gebruiken? Neem dan contact met ons op!
https://www.shintolabs.nl/wp-content/uploads/2021/12/Monitor-Vakantieparken-video-website.png15082862Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2021-12-23 16:02:102021-12-23 16:04:30Monitor Vakantieparken in gebruik en beschikbaar voor andere overheden
De antidiscriminatiebureaus of -voorzieningen (ADV’s) van de gemeenten Amsterdam, Rotterdam, Den Haag, Utrecht en regio Haaglanden (G4+) willen meer datagedreven gaan werken. Samen met Shintō Labs gaan ze een Analyse- en Rapportagetool ontwerpen en ontwikkelen op basis van het Stratum Analytics Platform. Het doel is om gebruik te maken van verschillende databronnen en deze te delen, makkelijker en flexibeler te kunnen rapporteren en meer inzicht te krijgen in trends en ontwikkelingen via een dashboard.
In Nederland kennen we een groot netwerk van voorzieningen die de burger bijstaan in geval van discriminatie. De antidiscriminatiebureaus of -voorzieningen (ADV’s) zijn daar het bekendste voorbeeld van. Sinds 2009 kent iedere gemeente de verplichting om zo’n meldpunt te hebben. De ADV moet minimaal de twee wettelijke taken uitvoeren:
Onafhankelijke bijstand bij de afwikkeling van discriminatieklachten
Registratie van de klachten
De ADV speelt daarnaast een rol van regievoerder en kennispartner voor de verschillende stakeholders in het speelveld. Denk hierbij aan politie, OM en diverse belangenbehartigers of non-profit organisaties gekoppeld aan de bestrijding van een of meerdere vormen van discriminatie.
Naar een datagedreven ADV
Om haar taken goed uit te kunnen voeren is de ADV afhankelijk van een goede informatiepositie. Op basis van deze informatiepositie kan zij beter beleid ontwikkelen en uitvoeren én meer regie voeren in een integrale ketenaanpak. Het is hierbij de ambitie dat iedere partner op basis van dezelfde inzichten handelt en haar aanpak afstemt.
Op dit moment registreren en verzamelen de ADV’s ook al data om die vervolgens om te zetten in rapportages. Problemen hierbij zijn o.a. dat data op verschillende plekken binnenkomt. Daarnaast is vergelijking van deze data lastig omdat verschillende definities bij registratie van fenomenen wordt gehanteerd. Daarnaast is de verwerking van de data in rapportages erg arbeidsintensief. Het pro-actief delen van data tussen ketenpartners om zo een beeld van de hele keten te krijgen en daarop een gezamenlijke aanpak te ontwikkelen is momenteel lastig.
Een analyse en rapportagetool voor de G4+
De ADV’s van de G4+ en de besturen van de aangesloten gemeenten, hebben de ambitie om de aanpak van de bestrijding van discriminatie te verbeteren en te professionaliseren. Enerzijds door een integrale ketengerichte aanpak en anderzijds door verbetering van de informatiepositie van de ADV’s. De G4+ zien zichzelf als proeftuin voor de andere 14 meldpunten die lid zijn van de Landelijke Vereniging tegen Discriminatie in Nederland.
Het analyse- en rapportagetool moet de volgende zaken mogelijk maken:
het verzamelen van data en maken van rapportages makkelijker en minder arbeidsintensief maken
trends en analyses kunnen doen op basis van de data en die ook geografisch visualiseren (bijv. op lokaal, gemeente, regionaal of landelijk niveau)
het ondersteunen van een integrale ketengerichte aanpak met de data en de inzichten die hieruit kunnen worden verkregen
een tool ontwikkelen dat schaalbaar is naar de andere ADV’s, gemeenten en ketenpartners in Nederland
We gaan begin volgend jaar starten met een Design Sprint om te komen tot een prototype van het analyse en rapportagetool.
Wil je op de hoogte blijven? Volg ons dan op social media of abonneer je op onze nieuwsbrief!
https://www.shintolabs.nl/wp-content/uploads/2021/12/Datagedreven-aanpak-discriminatie-website.jpg6391200Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2021-12-13 16:10:072021-12-13 16:10:07Naar een datagedreven aanpak van discriminatie met de Meldpunten Discriminatie van de G4+
Het A&O fonds Gemeenten vergeleek en analyseerde 18 voorbeeldprojecten van datagedreven innovatie. Op basis van die analyse kwamen zij tot negen factoren die bijdragen aan een succesvolle pilot met nieuwe technologie. De grote uitdaging is niet alleen om een succesvol experiment te doen maar deze ook om te zetten in werkende oplossingen en die vervolgens opschalen naar andere gemeenten.
Bij twee van de voorbeeldprojecten die worden beschreven zijn wij betrokken geweest:
de Woningbouw Monitor die we samen met de gemeente Eindhoven hebben ontwikkeld;
De Woningbouw Monitor is ontworpen en bedacht samen met de gemeente Eindhoven middels een Design Sprint. Het is het meest succesvolle voorbeeld van een datagedreven toepassing die we samen met de gemeente hebben ontworpen en ontwikkeld en inmiddels gebruikt wordt door meerdere gemeenten waaronder Zaanstad, Helmond en Groningen. Naar verwachting zullen de komende maanden nog zeker 10 gemeenten aansluiten.
De Woningbouw Monitor bestaat uit een beheeromgeving voor woningproductie data en diverse dashboards waarin deze data wordt gecombineerd met verschillende bronnen en inzichtelijk wordt gemaakt. De analisten kunnen realtime door de data zoeken en filteren en complexe data op eenvoudige wijze combineren tot heldere inzichten. Ook kunnen ze eerder inschattingen vergelijken met de actuele woningvoorraad om in te zien hoe de planning zich verhoudt tot de realiteit. Daarnaast kunnen ze op verschillende manieren rapportages maken waaronder de periodieke rapportage naar de provincie.
Onlangs hebben we een webinar georganiseerd waarin de de laatste ontwikkelingen hebben laten zien samen met de gemeente Eindhoven. Dit webinar is terug te kijken via deze link:
De gemeente Zaanstad wilde in de strijd tegen ondermijning de informatiepositie van de gemeente verbeteren. Samen hebben we een challenge benoemd en op basis daarvan is er een Design Sprint doorlopen.
‘Kunnen we door bronnen en signalen te combineren verschillende verschijningsvormen (zoals woon- en adresfraude, vastgoedfraude, uitkeringsfraude, hennepteelt, et cetera) inzichtelijk maken en van daaruit een effectieve aanpak ontwikkelen?’
In de Design Sprint is in vijf dagen op basis van de challenge een toetsbaar werkend prototype ontwikkeld voor het fenomeen woon- en adresfraude. In het ontwerpproces kwamen we erachter dat ondermijning meerdere verschijningsvormen kent en dat iedere verschijningsvorm eigen indicatoren, visualisaties en datasets kent. Deze fenomeenspecifieke kijk op de data noemen we een ‘lens’. Lees hier meer over in het whitepaper dat we erover hebben geschreven.
Het prototype is uitgebreid intern gevalideerd bij relevante stakeholders en extern bij andere gemeenten, en op basis van deze validatie is besloten het prototype door te ontwikkelen tot een data-applicatie die de gemeente Zaanstad inzicht gaat geven in woon- en adresfraude. Het idee bij de start was dat ook andere gemeenten de data-applicatie kunnen gebruiken, waarbij zij niet meer hoeven te investeren in de componenten die Zaanstad heeft ontwikkeld. Zo heeft dit jaar ook de gemeente Diemen besloten gebruik te maken van de applicatie en hebben we ook functionaliteit toegevoegd voor het beheer van signalen. Zie ook het artikel Gemeente Diemen kiest voor datagedreven aanpak woon- en adresfraude.
Op basis van de lessen van de pilots, waarbij datagedreven werken centraal staat, komt onder meer naar voren dat zeer vaardige projectleiders, het werken met multidisciplinaire innovatieteams en sterke drijfveren van betrokkenen om te vernieuwen doorslaggevend zijn. Ook leren van de markt en projecten op informele en cyclische wijze benaderen leidt vaak tot succes.
Alle Nederlandse regio’s werken hard om hun klimaatdoelstellingen te halen. Toch maken veel duurzaamheidsmedewerkers zich zorgen: doen we wel de juiste dingen? Dragen onze initiatieven wel echt bij aan het halen van onze doelstellingen? Hoe krijg ik de impact van onze initiatieven inzichtelijk, en hoe kan ik deze delen met onze inwoners, wethouders en partners? De gemeentes uit de regio Alkmaar vroegen zich dit af, en schakelden samen met Data Science Alkmaar onze hulp in.
Op maandag 4 oktober jl. organiseerden we een gezamenlijke co-creatie workshop. Zo’n 25 Duurzaamheids- en data-experts uit de regio Alkmaar, in samenwerking met Data Science Alkmaar en hoogleraar datagedreven businessinnovatie Frans Feldberg van de VU, bogen zich over de vraag welke rol data kan spelen in de energietransitie van de regio.
De Big Challenge(s)
Gezamenlijk identificeerden we drie ‘Big Challenges’: 1. Hoe kunnen we als gemeente het netcongestieprobleem samen met onze partners aanpakken? 2. Hoe kunnen we de impact van lokale initiatieven inzichtelijk maken? 3. Hoe brengen we de massa in beweging?
Deze drie big challenges vormen het startschot voor een onderzoek van Het PON & Telos. Zij onderzochten relevante indicatoren van de impact van lokale initiatieven, en ontwikkelden een meetplan – een duidelijke opvolger van de tweede tijdens de workshop geïdentificeerde Big Challenge. De eerste week van december namen wij het stokje van Het PON & Telos over.
De Design Sprint
We faciliteerden een Design Sprint om het meetplan en de indicatoren uit het onderzoek van Het PON & Telos om te zetten in een dynamisch, functioneel en, hopelijk, waardevol prototype. Ons sprintteam bestaat opnieuw uit duurzaamheids- en data-experts van de verschillende gemeentes in de regio Alkmaar, opnieuw aangevuld met Data Science Alkmaar, en onderzoekers van het PON & Telos.
We staan tijdens de Design Sprint, zoals altijd, uitgebreid stil bij het hoe en waarom: waarom is het belangrijk om de impact van duurzaamheidsintiatieven inzichtelijk te maken? Wat gaat er mis als ons dat niet lukt? Wie heeft zulk inzicht nodig, en met welk doel? En, misschien nog wel het belangrijkst: hoe brengen we de impact van duurzaamheidsinitiatieven zó in kaart dat dit bijdraagt aan nog impactvollere initiatieven in de toekomst, zoals activiteiten rondom het op handen zijnde netcongestieprobleem (big challenge 1) en het steeds meer in beweging krijgen van inwoners en bedrijven (big challenge 3)?
Een belangrijke factor hierbij was het grote aantal al bestaande dashboards rondom het thema duurzaamheid: hoe maken we optimaal gebruik van de kennis die al bestaat, en hoe zorgen we ervoor dat ons prototype een waardevolle toevoeging wordt? Op het moment van schrijven is deze Design Sprint nog in volle gang. Het definitieve prototype is dan ook nog niet bekend. Wel beginnen de contouren steeds helderder te worden.
Zo moet er ruimte blijven voor duurzaamheid en energietransitie in al haar complexiteit, moet het mogelijk worden om duurzaamheidsinitiatieven en -inspanningen te koppelen aan geagendeerde thema’s en geformuleerde doelen, en ziet het ernaar uit dat storytelling een belangrijk component van het prototype gaat worden. We’ll keep you posted!
Meer info?
Wil je meer weten over dit project? Neem dan contact met ons op via deze link!
https://www.shintolabs.nl/wp-content/uploads/2021/12/Co-creatie-energietransitie-duurzaamheid-Data-Science-Regio-Alkmaar-website.png18002880Shinto Labshttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngShinto Labs2021-12-05 12:51:512021-12-14 15:14:24Design Sprint energietransitie en duurzaamheid met Regio Alkmaar en Data Science Alkmaar
https://www.shintolabs.nl/wp-content/uploads/2021/11/Ondermijning-2021-naar-weerbare-wijke-en-structurele-aanpak-website-scaled.jpg17072560Shinto Labshttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngShinto Labs2021-11-05 16:36:552022-11-24 12:18:54Ondermijning in 2021: naar weerbare wijken en een structurele aanpak
De gemeente Apeldoorn werkt eraan om van de binnenstad een nog aangenamere plek te maken. Niet alleen om er te winkelen, maar ook om er te wonen en te verblijven. Dit doet de gemeente door meer in te zetten op onder meer groen en water en door te kijken naar het verkeer rondom en in de binnenstad. Sensordata helpt om inzicht te verschaffen in mogelijke effecten van interventies en ontwikkelingen. Shintō Labs ondersteunt de gemeente in de analyse van de sensordata met behulp van RStudio.
De klimaatstraat
Meer groen en water in de stad helpt bij het omgaan met klimaatverandering. Groen en water zorgen voor verkoeling op warme dagen en voor betere afvoer van regenwater. In de eerste klimaatstraat van Apeldoorn, de Marktstraat en Beekstraat, wordt hier volop op ingezet. Sensoren meten of de temperatuur ook echt daalt en of de lucht schoner wordt door de aanwezigheid van groen en water. Deze data kunnen helpen om ook in de rest van de binnenstad de juiste maatregelen tegen klimaatverandering in te zetten.
De gemeente wenst nu op basis van de sensordata te kijken of een aantal onderzoeksvragen beantwoord kunnen worden. Het betreft de volgende onderzoeksvragen:
Wat is het effect geweest van de Covid19-periode op de omgevingskwaliteit in de Binnenstad als het gaat om b.v. luchtkwaliteit en geluid?
Wat is het effect geweest van de elektrificering van het bussenpark op de omgevingskwaliteit in de Binnenstad als het gaat om b.v. luchtkwaliteit en geluid?
Wat is het effect geweest van de vergroening in de Marktstraat (Klimaatstraat) in Apeldoorn op de omgevingskwaliteit ten opzichte van andere plekken in de Binnenstad.
Shintō Labs
De gemeente Apeldoorn heeft Shintō Labs gevraagd om de sensordata te analyseren met behulp van RStudio en de onderzoeksvragen te beantwoorden. De gemeente wil vervolgens deze resultaten in haar eigen technische omgeving implementeren en uiteindelijk visualiseren in het Binnenstad-dashboard, dat zij in samenwerking met studenten van de hogeschool Saxion wil gaan ontwerpen en ontwikkelen.
Meer info?
Wil je meer weten over dit project? Neem dan contact met ons op via deze link!
https://www.shintolabs.nl/wp-content/uploads/2021/11/Apeldoorn-sensordata-website-2.png10781918Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2021-11-05 16:05:552021-11-05 16:05:55Sensordata uit de binnenstad analyseren voor Smart City Apeldoorn
https://www.shintolabs.nl/wp-content/uploads/2021/07/Birdseye-Eindhoven.png28835477Shinto Labshttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngShinto Labs2021-09-09 09:55:032021-09-09 10:56:19Stedelijke digital twins: wat kan je tweelingzus dat jij niet kan?