Deze maand starten we met een serie video’s waarin we onze kennis delen onder de noemer: Shintō Labs Masterclass. In iedere editie komt een expert aan het woord om over een specifiek onderwerp zijn of haar kennis te delen. We gaan in op verschillende vraagstukken rondom datagedreven werken en data analytics in de overheid. Onderwerpen kunnen variëren van innovatie methodiek, privacy, ethiek maar ook meer technische onderwerpen als netwerkanalyses en graph databases.
Text Analytics en Machine Learning in de overheid
In deze editie vertelt data scientist Martijn Heijstek over een toepassing van Text Analytics en Machine Learning in de overheid. Hij behandelt de case waarin content automatisch wordt geclassificeerd in het verlengde van een zaaksysteem: in dit geval Djuma van Visma|Circle.
Vragen en feedback
Heb je een vraag of opmerkingen over de vodcast van Martijn? Laat het ons dan weten via onderstaand formulier!
Abonneren
Wil je automatisch op de hoogte blijven van nieuwe edities van de Shintō Labs Masterclass? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via bovenstaand formulier en vink de ‘blog’ optie aan!
https://www.shintolabs.nl/wp-content/uploads/2020/04/Vlog_Text_Analytics_overheid_WP.png16182878Shinto Labshttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngShinto Labs2020-04-21 18:17:592020-05-28 15:33:35Masterclass – Text Analytics en Machine Learning in de overheid
De afgelopen elf maanden ben ik ondergedompeld in de wereld van data. Via de ’track’ Data Science als onderdeel van Information Studies aan de UvA kwam ik in contact met allerlei toffe algoritmes en maakte ik kennis met de problematiek achter de technische hoogstandjes. Een van deze problemen was gericht op ondermijning in Amsterdam en bij het zoeken naar vergelijkbare projecten kom je dan al snel uit bij Shintō Labs.
Met zwetende handjes heb ik een voorzichtig mailtje gestuurd naar het ‘Shinteam’ of ik ‘heel misschien’ en ‘alleen als het uitkomt’ langs mocht komen om de mogelijkheid tot een afstudeerstage te bespreken. Wat ik niet verwachtte is dat de daaropvolgende uitnodiging zo relaxed en soepel verliep dat ik direct verkocht was. Daar wil ik graag mijn thesis schrijven! Inmiddels zijn we vijf maanden verder en is het papiertje op zak en ik kan wel stellen dat ik geen spijt heb van deze keuze. Natuurlijk was het hard buffelen, maar het waren ook enorm leerzame maanden waarbij ik vanaf dag één door het team ben opgenomen. Ook nam ik deel aan de Design Sprint met het RIEC Rotterdam en Bureau Beke op het thema Risico Radar Ondermijning, waarbij we op basis van open bronnen de mogelijke hotspots inzichtelijk maken. In deze sprint kon ik mijn onderzoek mooi toepassen.
In deze blog beschrijf ik mijn onderzoeksopzet en de eerste resultaten. In de onderstaande video kun je ook de presentatie zelf zien.
De casus
De core business van Shintō Labs bestaat uit het maken van datagedreven applicaties voor overheidsinstellingen. Vaak bevat een applicatie een dashboard met een kaart waarop dan data is geplot. In verband met privacy wordt die data vaak gepresenteerd per postcode, buurt of wijk (en dus niet per huis of gebouw).
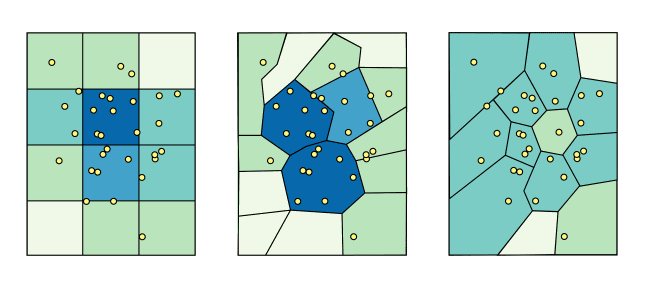
De keuze voor het type gebiedsindeling kan echter een vertekenend beeld geven van de werkelijkheid. In figuur 1 zie je bijvoorbeeld drie representaties van exact dezelfde data, maar met verschillende gebiedsindelingen. Dit probleem staat in de boeken bekend als MAUP – The Modifiable Area Unit Problem. Dit fenomeen doet zich ook voor wanneer we data presenteren per postcode, buurt of wijk: hoe meer variatie er in zo een gebied plaats vindt, hoe meer informatie wordt weggegooid wanneer de data wordt geaggregeerd.
Figuur 1 Voorbeeld van ‘The Modifiable Area Unit Problem’
Een manier om dit probleem aan te pakken is door gebiedsindelingen datagestuurd te maken. Als we de bestaande wijken/buurten loslaten en kijken naar de achterliggende data, dan kunnen we gebieden creëren die de mensen in het gebied zo veel mogelijk vertegenwoordigen. Dit doen we door middel van geodemografie; ‘The study of people by where they live’ (Harris, 2005).
Geodemografie
Zoals de naam al prijs geeft is dit vakgebied een combinatie van geografie en demografie, waarmee de data ook direct complex wordt. In geodemografie word er gezocht naar betekenisvolle bundels om de mensen in een gebied te kunnen beschrijven. Deze bundels worden in de literatuur ook wel micro-communes of urban neighbourhoods genoemd. Door middel van algoritmen worden mensen ingedeeld in clusters, die vervolgens worden geplot op een kaart. In principe volgt iedere geodemografische clustering ruwweg hetzelfde proces van datapreparatie, algoritmeselectie en parameterselectie, maar het probleem ontstaat bij de evaluatie. Want wat zijn betekenisvolle clusters? Dat is een bijna filosofische vraag, die niet zomaar beantwoord kan worden. Voor de fijnproevers raad ik het paper van ‘What are true clusters’ aan van Christian Hennig.
Figuur 2. Voorbeeld van een geodemografische clustering van Eindhoven. Bron: CBS
Geodemografische cluster-evaluatie
In tegenstelling tot standaard ‘gesuperviseerde methoden’ is het valideren van een geodemografische clustering een schemerig gebied tussen kunst en wetenschap, het kwantitatieve en het kwalitatieve, objectiviteit en subjectiviteit (Harris, 2005). Zoals mijn docent het noemt, is cluster-evaluatie in feite een vorm van zwarte magie.
Binnen de geodemografie is er wel een idee van enkele eigenschappen die een clustering betekenisvol maken, waarvan de belangrijkste eigenschap is, dat de clustering aansluit bij het doel en de context van het clusterprobleem. Om dat doel meetbaar te maken gebruiken we interne en/of externe criteria die helpen bij het maken van de keuze van het algoritme en de parameter instellingen.
De externe criteria bestaan soms uit vergelijkingen met referentieclassificaties of een zogenoemde ground truth. Veel vaker worden subjectieve criteria opgelegd met behulp van experts of de eindgebruikers. De interne evaluatie van een clustering bestaat uit het meten van een bepaalde regel die de data beschrijft zoals ‘hoe compact zijn de clusters?’ of ‘wat is de ratio tussen de gemiddelde inter en intra clusterafstand?’. Hoewel deze regels objectief zijn, is het wel de vraag hoeveel waarde je moet hechten aan de resulterende waarden en hebben deze regels zeker niet altijd toegevoegd nut. Over het algemeen wordt interne evaluatie daarom vooral gebruikt om het cluster proces te sturen en niet te leiden (Alexiou, 2017).
De interne evaluatie regels hebben nog een extra uitdaging, want deze methoden zijn over het algemeen niet aangepast aan geodemografische clustering. De meest gebruikelijke metrieken (zoals de Within-cluster sum-of-squares en de Silhouette index) worden alleen toegepast op de demografische data en niet op de geografische data. Dit terwijl ´echte’ microcommunes samenhang lijken te vertonen in zowel de geografische als demografische ruimte (Wolf et al., 2019).
De kern
In mijn onderzoek heb ik geprobeerd een regel op te stellen die speciaal geadapteerd is voor geodemografische data. Deze regel is gebaseerd op de Silhouette score, maar met een speciale functie die afstand kwantificeert als combinatie van geo- en demografische data. Er zitten aan een dergelijke functie nog flink wat haken en ogen: hoe verhoudt bijvoorbeeld geografie zich tot demografie? Uiteindelijk hebben we als ‘proof of concept’ de aanpak van Wolf et al. overgenomen (inmiddels liep de onderzoeksperiode al tegen het einde).
Uit een kleinschalig experiment komt naar voren dat de geodemografische score wel degelijk wat interessante patronen vertoont. Zeker ten opzichte van de conventionele (non-geografische) Silhouette score lijkt de nieuwe regel een stuk minder triviale patronen weer te geven. Dit bleek ook uit de validatie (feedback van gebruikers) van het prototype van de Risico Radar Ondermijning zoals ik die heb gerealiseerd voor het RIEC Rotterdam.
Lessons learned
Het voorgaande stuk ging vrij snel de diepte in en eindigt tamelijk theoretisch. Maar wat zijn nu de take home wijsheden die we tijdens het onderzoek zijn tegengekomen?
Een van de belangrijkste redenen om interne evaluatie regels te zoeken is om subjectiviteit in geodemografie te verminderen. We willen graag goed gefundeerde keuzes maken tijdens het clusterproces en idealiter is geodemografie zo transparant mogelijk. In de praktijk blijven de objectieve evaluatie technieken slechts een onderdeel van het clusterproces, waar de keuzes voor het algoritme en de parameter instellingen uiteindelijk worden gemaakt door mensen. Het maken van een geodemografische clustering is niet moeilijk, maar een goede geodemografische clustering maken is een flinke uitdaging, die ook afhangt van de context.
Hoe nu verder?
Tot nu toe hebben we een paar keer genoemd dat interne validatie regels vooral ‘betekenis’ krijgen in het kader van een context en met een expert/gebruiker om de context te interpreteren. Hoewel mijn thesis vooral de theorie van geodemografische evaluatie beslaat, zijn we natuurlijk erg benieuwd of de interne regels ook echt hulp bieden tijdens het clusteren. Daarom ben ik met het Shintō Labs team begonnen aan een interactieve module waarmee je je eigen (geodemografische) data kan clusteren. De module geeft adviezen op basis van de interne evaluatie regels, maar uiteindelijk is het aan de gebruiker om de waarde van de clustering in te schatten. Voor nu blijft het dashboard bij een prototype, maar mocht je interesse hebben in deze applicatie, neem dan contact op met het Shintō Labs.
Figuur 3. Prototype van het dashboard
Referenties
Alexiou, A. (2017). Putting ’Geo’ into Geodemographics: evaluating the performance of national classification systems within regional contexts. PhD thesis, University of Liverpool.
Harris, R., Sleight, P., and Webber, R. Geodemographics, GIS and Neighbourhood Targeting. Wiley, London, UK, 2005
Hennig, C. (2015). What are the true clusters?. Pattern Recognition Letters, 64, 53-62.
Wolf, L., Knaap, E., and Rey, S. J. (2019). Geosilhouettes: geographical measures of cluster fit.
https://www.shintolabs.nl/wp-content/uploads/2019/08/blog_martijn.jpg6731200Martijn Heijstekhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngMartijn Heijstek2019-09-15 16:07:502022-10-13 13:43:32Onderzoek: hoe geodemografie kan helpen om data ‘eerlijker’ weer te geven
‘De gemeente Rotterdam stopt omstreden fraudeonderzoek met SyRi,’ kopte de Volkskrant op 4 juli jl. Een van de vele berichten de afgelopen tijd waarin het gebruik van data-analyse of erger ‘algoritmes’ negatief in het nieuws komt. Recent publiceerde de NOS nog een fraai artikel getiteld ‘Overheid gebruikt op grote schaal voorspellende algoritmes, ‘risico op discriminatie’. Ook hier ontstaat (in ieder geval door de kop) het beeld dat er sprake is van wildgroei en het ‘kwaad’ zich verder verspreidt zonder dat er grip op is. De begeleidende podcast van de journalisten geeft een genuanceerder beeld. We horen de journalist zelfs zeggen dat het begrijpelijk en goed is dat de overheid gebruik maakt van moderne technologie.
De discussie is terecht. Het gebruik van algoritmes kent risico’s. Maar het lijkt niet goed te lukken om het gesprek over algoritmes genuanceerd en goed geïnformeerd te voeren. Alleen al het woord algoritme zorgt voor een soort verkramping in de discussie en lijkt de gebruiker ervan in het beklaagdenbankje te zetten. Als bedrijf dat de overheid helpt om datagedreven te werken, waren we ons vanaf het begin bewust van de risico’s en ontwerpen en ontwikkelen we op een verantwoorde manier oplossingen. Niet omdat de publieke opinie daarom vraagt, maar omdat we een eigen moreel kompas hebben.
Omdat we vaker vragen krijgen over de ethische kanten van het gebruik van algoritmes hebben we een aantal handvatten op een rij gezet. Geen doorgrond essay, of concreet raamwerk, maar een aantal ervaringen uit onze praktijk. Omdat we open zijn over hoe wij omgaan met de risico’s van het gebruik van algoritmes.
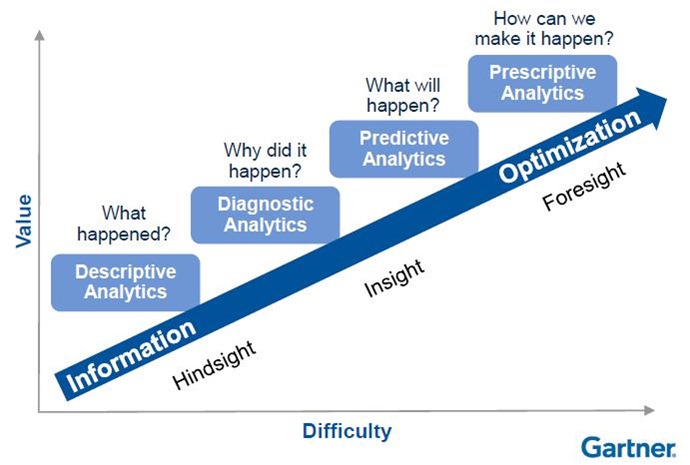
1. Gebruik geen voorspellende algoritmes (als het niet nodig is)!
Ik geeft toe. Een beetje een dooddoener. Het begint natuurlijk bij de vraag: wat zijn voorspellende algoritmes? Ik ga er vanuit dat hiermee bedoeld wordt het begrip ‘predictive analytics’. Een methode waarmee veelal op basis van machine learning voorspellingen worden gedaan. Maar de wereld van data-analyse is breder dan alleen voorspellende algoritmes. Sterker nog: in onze praktijk zetten we predictive analytics vaak niet eens in. Zeker niet in onze oplossingen in het domein van toezicht & handhaving of veiligheid & openbare orde. Waarom niet? Omdat we geloven in ‘waardegestuurde’ ontwikkeling. Zie ook ons blog ‘Van datagestuurd naar waardegestuurd werken’. In het kort: zet het probleem en de gebruiker centraal en kijk van daaruit welke pijn het grootst is. Keer op keer blijkt dat de meeste waarde in eerste instantie wordt toegevoegd met een ‘beschrijvende analyse’. Niks voorspellingen op basis van machine learning dus, of in ieder geval niet vóór dat we weten waar de waarde zit, wat de feitelijke situatie is (beschrijvende analyse) en waar het probleem zit (diagnostisende analyse). Pas als aan die voorwaarden is voldaan kan er voorzichtig gekeken worden naar voorspellingen. Tot die tijd: gebruik geen voorspellende algoritmes!
Bron: Gartner
2. Wees transparant over data en modellen!
Zoals je in het artikel van de Volkskrant kunt lezen is een van de grootste obstakels bij SyRi dat voor de gebruiker niet duidelijk is op basis van welke datasets en indicatoren er een inzicht wordt verschaft. Omdat wij onze oplossingen ontwerpen vanuit gebruikersperspectief herkennen we hun behoefte om te weten op basis waarvan het systeem ergens een ‘rood puntje laat knipperen’. Zo zijn we voor de gemeente Zaanstad een data applicatie aan het ontwikkelen die de gemeente helpt bij het opsporen van o.a. woonfraude waarbij vanuit de applicatie inzichtelijk is welke datasets zijn gebruikt en op basis waarvan een indicatie wordt gegeven.
Screenshot prototype Ondermijning met beschrijving datasets en indicatoren
3. Gebruik indicatoren op basis van gedegen onderzoek!
Een veelgehoorde vrees is dat data-applicaties inzichten bieden die discrimineren. Data is immers niet objectief! Zeker bij het gebruik van ‘feedback loops’ zal een model leren op basis van ervaringen (data) uit het verleden en dat verleden bevestigen en versterken. Wat is dus een deugdelijk indicatie om bijvoorbeeld een pand te onderzoeken of daar iets mis is? Vaak vertalen we indicatoren van de (vak)mensen uit de praktijk naar het model maar proberen dat ook te onderbouwen door (wetenschappelijk) onderzoek. Zo hebben we met het RIEC Rotterdam een Risico Radar Ondermijning ontwikkeld waarbij Bureau Beke op basis van literatuuronderzoek en expert interviews een lijst van 52 indicatoren samengesteld die wij hebben gebruikt om zicht te krijgen op risico’s op ondermijning door bedrijven. In september organiseren we samen met het RIEC en Bureau Beke een webinar waarin we hier meer over vertellen. Zijn deze indicatoren daarmee allemaal 100% objectief? Nee, maar wel binnen de normen van de (gedrags-)wetenschap als significant bestempeld.
Jurriaan Souer (Shintō Labs) in actie met dr. Henk Ferwerda van Bureau Beke, onderzoeksbureau voor criminologische vraagstukken
4. Laat systemen niet beslissen, maar help de expert!
Er zijn (soms schrijnende) voorbeelden van Kafkaëske situaties waarbij de overheid besluiten neemt waar de mens geen grip meer op heeft. ‘Computer says no.’ De angst is dat voorspellende algoritmes besluiten nemen zonder dat er een mens aan te pas komt. Als ik dan roep dat zoiets nooit moet kunnen, dan zegt mijn collega Jurriaan relativerend tegen me: ‘Dus ook niet bij slimme vuilnisbakken die automatisch opdracht geven aan de vuilnisophaaldienst om geleegd te worden?’. Tja, daar natuurlijk wel. Maar in onze praktijk komt het zelden voor dat gebruikers één antwoord willen, laat staan een geautomatiseerd besluit. Ze willen een instrument dat ze helpt om op basis van hun eigen expertise makkelijker of sneller inzicht te krijgen dan nu het geval is. We kennen voorbeelden van beleidsambtenaren uit het veiligheidsdomein die na een melding soms anderhalve dag kwijt zijn om in 15 systemen te kijken om te bepalen of er iets aan de hand is. Het enige dat we doen is de data sneller aanleveren dan nu en deze zodanig visualiseren dat de expert kan besluiten om al dan niet tot actie over te gaan. We helpen dus bij het maken van een risico inschatting.
5. Realiseer je dat ‘bias’ in de mens zit en daarmee ook in de data
Tijdens onze Design Sprints, het startpunt van onze ontwikkeling, nemen we veel tijd om gebruikers te laten vertellen over het vraagstuk. We willen weten hoe ze daar nu mee omgaan, dus zonder data-analyse en algoritmes. Als wij met mensen uit de wereld van toezicht en handhaving praten en ze vragen waar risico op een overtreding is, dan kunnen ze zo een lijstje van risicoindicatoren oplepelen. Hoe ze daarbij komen? Ervaring. Als jij bij controles meerdere keren fraude aantreft bij een bepaald soort bedrijven dan word je als handhaver alerter en controleer je vaker bij dat soort bedrijven. Is dat terecht? Misschien wel, misschien niet. In iedere geval heel menselijk. Dataprojecten versterken niet de bias. Ze leggen die juist bloot.
Bron: https://dilbert.com/
Tot slot
Ik zat laatst het radioprogramma BNR Digitaal te luisteren toen ik Rudy van Belkom hoorde zeggen: ‘We hebben het altijd over ‘explainable AI’ maar hoe ‘explainable’ is menselijk gedrag eigenlijk?’ Een mooi inzicht wat mij betreft. Geen complexer neuraal netwerk dan het menselijk brein. Discriminatie is een product daarvan. Laten we ons dus met of zonder algoritmen daarvan bewust blijven. Waar het om gaat, is dat we de uitwassen tot een minimum beperken.
P.s. binnenkort zal onze Chief Data Scientist Eric een vervolg op dit blog schrijven hoe we in technische zin het risico op ‘bias’ proberen te minimaliseren. Wil je automatisch bericht ontvangen via email als dat blog verschijnt? Schrijf je dan hier in.
https://www.shintolabs.nl/wp-content/uploads/2019/07/alexandra-gorn-smuS_jUZa9I-unsplash.jpg14994005Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2019-07-05 22:35:182019-07-11 11:18:415 praktische handvatten om ‘algoritmekramp’ tegen te gaan