Negen innovatieve ideeën voor de Woningbouw Monitor
Onze trouwe volgers weten dat de ‘Lean Startup’ een belangrijke inspiratiebron voor ons denken en doen is. In het kort: hoe kunnen we ideeën zo snel mogelijk toetsen op waarde alvorens we tijd en energie in de realisatie ervan gaan stoppen. Ook bij de doorontwikkeling van onze producten hanteren wij deze aanpak, waarbij we eerst proefversies (of ‘beta-versies’) van functies beschikbaar stellen om feedback op te halen bij onze gebruikers. Hoe ziet dat eruit? In dit blog belichten we 9 nieuwe ideeën voor de Woningbouw Monitor.
Het ‘Labs’ onderdeel van de Woningbouw Monitor is een verzameling innovatieve functionaliteiten (in ontwikkeling) die het productteam van Shintō Labs ontworpen heeft om gebruikers van de Woningbouw Monitor nog beter te ondersteunen. De nieuwe functies zijn nog niet helemaal uitontwikkeld, maar geeft de gebruikers van de Woningbouw Monitor wel de mogelijkheid om ze in een vroeg stadium uit te proberen en daar feedback op te geven,

Figuur 1: het ‘Labs’ onderdeel van de Woningbouw Monitor
Voor iedereen die zich aangemeld heeft is een nieuw menu item ‘Labs’ in de Woningbouw Monitor beschikbaar. Labs is permanent in ontwikkeling en de inhoud is dan ook aan verandering onderhevig. Op moment van schrijven bevat Labs negen nieuwe functionaliteiten die ik hieronder zal toelichten:
- Snel overzicht plot
- Uitval prognose
- Vertraging analyse
- Doelstellingen plot
- BAG Woningvoorraad+
- Vergunningen
- Conversie
- Rubik’s Cube
- Rapportage lab
1. Snel overzicht plot
Probleem: specifieke (afwijkende) grafieken
De Woningbouw Monitor heeft verschillende grafieken en overzichten voor de beleidsmedewerkers. De veelvoorkomende vragen zoals: aantallen woningtypen, projectfase, opleverjaren, prijsklassen, huur/koop, sociale huur, etc. en zowel cumulatief als jaarlijks worden standaard meegeleverd en reageren bovendien op de filters aan de rechterkant. Maar, vaak zijn er specifieke vragen die nét niet in een standaard grafiek passen. Uiteraard kan alle data te allen tijde geëxporteerd worden naar Excel voor verder analyse en grafiekjes, maar soms wil de beleidsmedewerker even snel een eigen dwarsdoorsnede maken van de data.
Oplossing: zelf grafieken samenstellen
Met de Snel Overzicht Plot kan een beleidsmedewerker zelf grafieken samenstellen op basis van enkele parameters. Kies zelf welke groepen je wilt gebruiken en hoe je de kleurverdeling wenst. Kies vervolgens de gewenste opmaak zodat het visueel aan je wensen voldoet. Maak op deze manier in een handomdraai je eigen grafieken en sleep het grafiekje zo naar je Word-rapportage of presentatie.
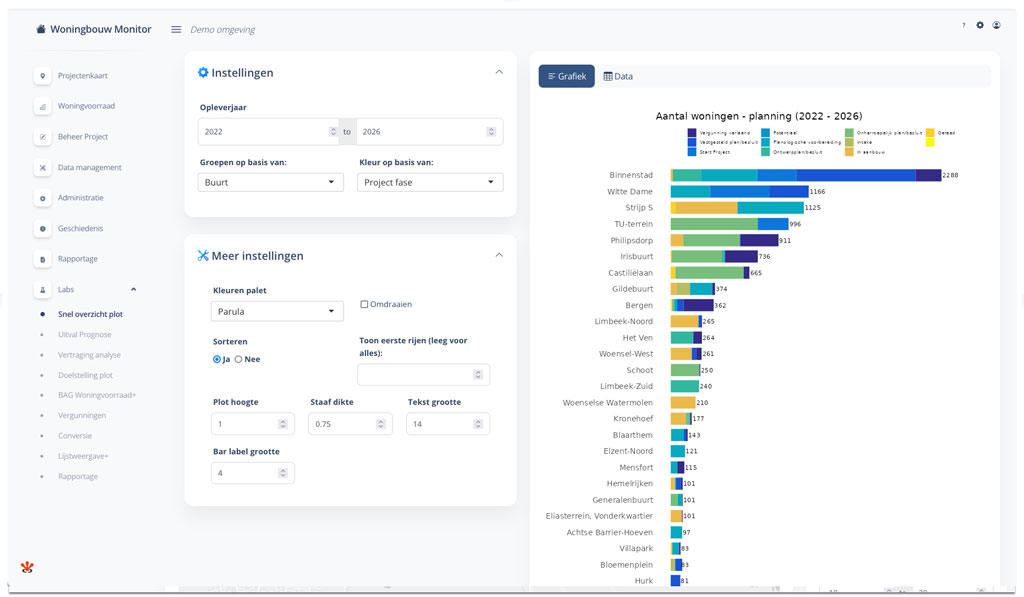
Figuur 2: Snel overzicht plot
2. Uitval prognose
Probleem: “what if”-scenario’s doorrekenen
De Woningbouw Monitor is een cijfermatige werkelijkheid. Maar wie zegt dat alle projecten die in Planologische voorbereiding zitten ook daadwerkelijk gebouwd gaan worden? Iedereen die actief is in de woningbouw weet dat er altijd een mate van onzekerheid is – zeker nu. Hoe gaan we om met dit soort onzekerheden en halen we dan onze doelstelling wel?
Oplossing: Uitval Prognose
Met de uitval prognose kun je aangeven per projectfase hoe groot de kans is dat de woningen in de projecten binnen die fase ook daadwerkelijk gerealiseerd worden. Met een zekere bandbreedte en inschatting kan op die manier een aantal “what-if”-scenario’s worden doorgerekend.
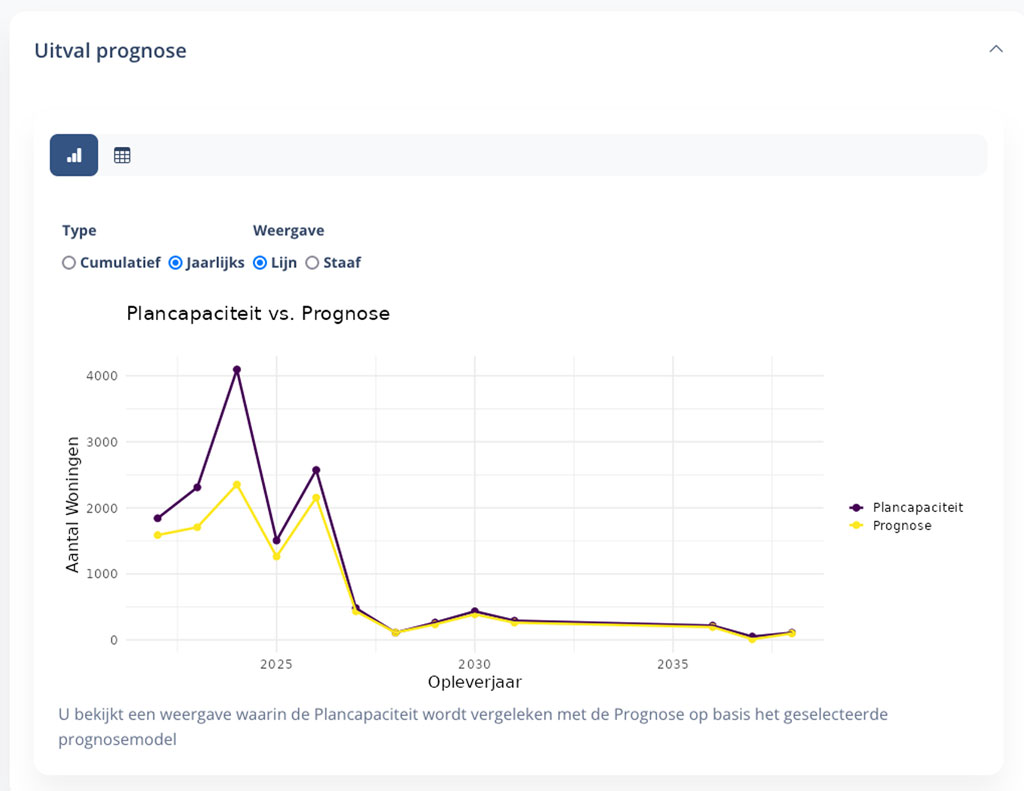
Figuur 3: Uitvalprognose
3. Vertraging analyse
Probleem: Hoe weet je wat de kans is dat een project vertraagd?
Dat projecten vertragen is nu eenmaal een feit. Maar wat zijn kenmerken waardoor projecten vertragen? Welke factoren dragen daar aan bij?
Oplossing: Voorspellend model
Om deze vraag te beantwoorden hebben we met hulp van machine learning een decision tree gemaakt om een voorspelling te maken van het risico op vertraging. Je kunt zelf parameters kiezen die meegewogen worden in de analyse en het systeem geeft antwoord op de vraag welke factoren een rol hebben gespeeld.
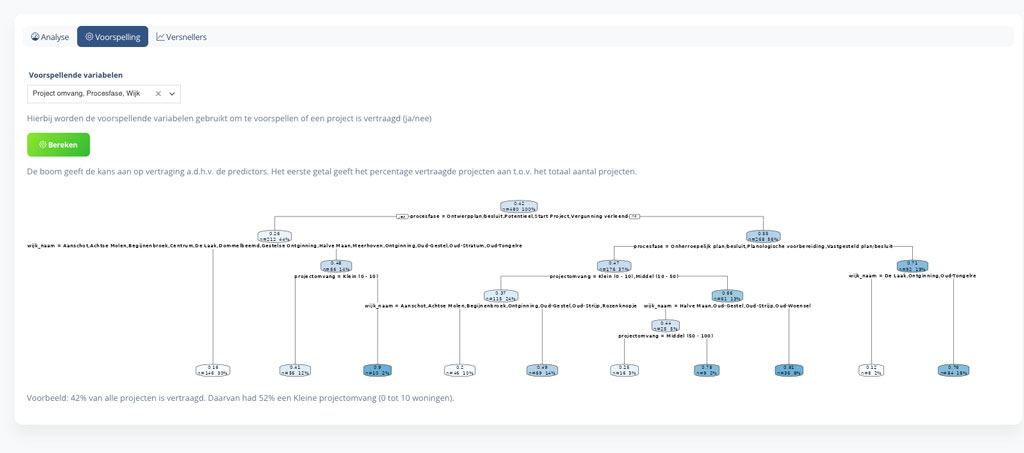
Figuur 4: Vetragingsanalyse
4. Doelstellingen plot
Probleem: Halen we specifieke doelstellingen? En met welke scenario’s halen we onze doelstellingen ?
De programma match is een standaard functionaliteit van de Woningbouw Monitor, maar die geeft vooral aan men op koers ligt voor de algemene doelstellingen zoals gedefinieerd in het woonprogramma. Maar wat als we specifieke extra doelstellingen hebben? En verschillende scenario’s willen bekijken om te zien of dat haalbaar is?
Oplossing: Doelstellingen plot
Met de doelstellingen plot kunnen verschillende scenario’s doorgerekend worden om de oplevering per jaar te bepalen. Wat als we ‘x’-aantal woningen per jaar in de categorie ‘huur’ en ‘y’-aantal woningen in de categorie ‘koop’ realiseren, komen we dan uit met onze doelstellingen? Met dit soort scenario’s kan geanticipeerd worden op de beoogde doelstellingen.
5. BAG Woningvoorraad+
Probleem: Wat zit er op dit moment allemaal in mijn buurt/wijk/dorp/stad ?
In de basis hadden we vooral de BAG als bron voor de woningvoorraad. Maar steeds meer komt er vraag om meer kenmerken toe te voegen. Hoe staat het met de gezinssamenstelling? Inkomen? En andere sociaal-demografische voorzieningen? Maar ook: welke voorzieningen zijn er in de buurt? Deze informatiebehoefte is noodzakelijk voor de beleidsmedewerkers om de juiste afwegingen te maken, adviezen te geven en te rapporteren.
Oplossing: Meerdere bronnen combineren en inzichtelijk maken in de Woningvoorraad+
Met de BAG Woningvoorraad+ bieden we precies een antwoord op bovenstaande vragen. We combineren BAG data met CBS data en OSM om een goed beeld te geven wat er speelt in een buurt/wijk/dorp/stad. Je kunt op gemeente niveau, of een kleinere geografische eenheid kiezen (of zelf een gebied intekenen) en alle relevante informatie bevragen en samenvatten.
6. Vergunningen
Probleem: Zijn er relevant vergunningen afgegeven?
Om de informatiepositie van de beleidsmedewerker te versterken is er de behoefte om ook inzage te krijgen in welke vergunningen er afgegeven zijn. Een melding van een relevante vergunningen kan voor de beleidsmedewerker een signaal zijn om bepaalde projecten aan te passen of om contact op te nemen met de betreffende afdeling om de details op te vagen.
Oplossing: Vergunningen
De Vergunningen functionaliteit doet eigenlijk wat je zou verwachten: het ‘luistert’ naar een open data set met gepubliceerde vergunningen, filtert die op relevantie en laat die in een overzicht zien. Aan de hand van de voorkeuren van de beleidsmedewerker kan deze datastroom geoptimaliseerd worden.
7. Conversie: data conversie monitor
Probleem: Datakwaliteit van integraties waarborgen
De Woningbouw Monitor heeft soms integraties met achterliggende systemen uit de ‘back office’ van een gemeente. Die data wordt dan periodiek opgehaald, opgeschoond en ingelezen. De data is echter zelden volledig opgeschoond, van hoge kwaliteit, en betrouwbaar. Hoewel het wel mogelijk is om geïmporteerde data te wijzigen in de Woningbouw Monitor wordt dit idealiter in de bron aangepast. Maar hoe hou je zicht op wat er wel en wat er niet goed gaat?
Oplossing: Data conversie monitor
De data conversie monitor houdt keurig bij welke import wanneer is gedaan en wat er wel en wat er niet goed is gegaan. Zo ontstaat er een uitval lijst waarmee de bron eigenaren de nieuwe data import in een aantal iteraties kunnen optimaliseren. Bekijk het webinar met de gemeente Ede over hoe zij op deze manier in enkele slagen de uitval lijst met 90% hebben weten te reduceren.
8. Rubik’s Cube
Probleem: Datasets grouperen en kantelen
De datastructuur van de Woningbouw Monitor is opgebouwd uit rijen met project (en deelproject) informatie. Maar soms wil je de data ook ‘kantelen’ of op een andere manier ‘groeperen’, net als bij de Rubik’s Cube.
Oplossing: Rubik’s Cube
De Rubik’s Cube is een nieuwe module waarbij je bestaande datasets kunt groeperen en kantelen om zo nieuwe inzichten te krijgen en nieuwe rapportages te maken. Dit wordt typisch gebruikt in een gemeente met meerdere kernen om zo de data te groeperen per woonkern en dit verder uit te splitsen. De Rubik’s Cube is een hele leuke nieuwe toevoeging die veel gebruikt wordt
9. Rapportage
Probleem: Eigen rapportages
Shintō Labs levert standaard de provincierapportage en daarnaast kunnen alle selecties altijd geëxporteerd worden (naar Excel). Maar soms willen gemeentes een eigen rapportage voor specifieke overleggen. Dat kan zijn op basis van bepaalde kenmerken of statussen (bijvoorbeeld: groepeer alle projecten met juridische status ‘in aanbouw genomen’), soms op basis van geografische eigenschappen ‘binnen de ring’ en ‘buiten de ring’, etc. Dit soort maatwerk Excel rapportages worden door gemeentes gebruikt bij overleggen rondom prioritering.
Oplossing: Rapportages
Shintō Labs heeft om die reden een module ontwikkeld voor eigen rapportages waarbij de beleidsmedewerker met een druk op de knop de gewenste rapportage gepresenteerd krijgt. Afhankelijk van hoe generiek de wensen zijn worden deze rapportages standaard aangeboden in het Lab voor andere gemeentes.
Dit zijn negen voorbeelden van functionaliteiten die uit de Labs van de Woningbouw Monitor komen. Er zijn nog meerdere functionaliteiten in ontwikkeling. Mocht je hiervan op de hoogte willen blijven, schrijf je dan in voor onze nieuwsbrief of neem gerust contact met ons op.
Zie ook
Webinar
- Webinar ‘Monitoren Woningbouwopgave in de gemeente Ede’
- Webinar ‘Woningbouw versnellen en monitoren met de dynamische Projectenkaart’
- Webinar Woningbouw Monitor met Brigitte Cavens van de gemeente Eindhoven
Whitepapers
- Whitepaper ‘Naar datagestuurd woonbeleid’
- Whitepaper ‘Van maatschappelijke opgave naar datagedreven toepassing’
Nieuws
- Datagedreven aanpak woningbouwopgave in de Gemeente Moerdijk
- Regionale monitoring woningbouwprojecten in het Stedelijk Gebied Eindhoven
- Gemeente Leiden gaat aan de slag met de Woningbouw Monitor
- Gemeente Ede kiest voor de Woningbouw Monitor
- Capital Value en Shintō Labs lanceren de Nationale Woningbouw Monitor
- Woningbouw Monitor 3.0 beschikbaar voor gemeenten
- Acht gemeenten in Noord-Holland samen aan de slag met de Woningbouw Monitor
- Gemeente Groningen aan de slag met datagedreven woonbeleid
- Gemeente Helmond kiest voor de Woningbouw Monitor
- Gemeente Eindhoven kiest voor datagestuurde aanpak woningopgave
Blogs
- Zes tips voor Minister de Jonge en de Tweede Kamer
- Storytelling met data: hoe maak je een goede data story?
- Storytelling met data: een goed verhaal zegt meer dan duizend taartdiagrammen
- Onze 10 data science trends voor 2021
- Waarom de Design Sprint dé oplossing is voor datagestuurd werken
- Van datagestuurd naar waardegestuurd werken
- Vijf redenen waarom je datagedreven werken als gemeente samen moet doen
Testimonials
- Interview Gooitske Marsman van de gemeente Helmond
- Interview Tom Pots van de gemeente Zaanstad
- Interview Gaby Rasters van de gemeente Eindhoven
Foto credit: Michael Bader op Unsplash