Deze maand zijn we gestart met een serie video’s waarin we onze kennis delen onder de noemer: Shintō Labs Masterclass. In iedere editie komt een expert aan het woord om over een specifiek onderwerp zijn of haar kennis te delen. We gaan in op verschillende vraagstukken rondom datagedreven werken en data analytics in de overheid. Onderwerpen kunnen variëren van innovatie methodiek, privacy, ethiek maar ook meer technische onderwerpen als netwerkanalyses en graph databases.
Correctie van bias-versterkende feedbackloops
In deze editie vertelt CTO en Co-founder Eric van Esch over de rol van bias (onbewuste vooroordelen) in algoritmes, of zoals hij dat liever noemt: algoritmische systemen, en wat je daar tegen kunt doen. Naast theoretische kennis worden ook voorbeelden uit onze praktijk besproken zoals de Milieu Navigator en onze Risico Radar Ondermijning.
Vragen en feedback
Heb je een vraag of opmerkingen over de vodcast van Eric? Laat het ons dan weten via onderstaand formulier!
Abonneren
Wil je automatisch op de hoogte blijven van nieuwe edities van de Shintō Labs Masterclass? Abonneer je dan op ons Youtube kanaal of stuur ons bericht via bovenstaand formulier en vink de ‘blog’ optie aan!
‘De gemeente Rotterdam stopt omstreden fraudeonderzoek met SyRi,’ kopte de Volkskrant op 4 juli jl. Een van de vele berichten de afgelopen tijd waarin het gebruik van data-analyse of erger ‘algoritmes’ negatief in het nieuws komt. Recent publiceerde de NOS nog een fraai artikel getiteld ‘Overheid gebruikt op grote schaal voorspellende algoritmes, ‘risico op discriminatie’. Ook hier ontstaat (in ieder geval door de kop) het beeld dat er sprake is van wildgroei en het ‘kwaad’ zich verder verspreidt zonder dat er grip op is. De begeleidende podcast van de journalisten geeft een genuanceerder beeld. We horen de journalist zelfs zeggen dat het begrijpelijk en goed is dat de overheid gebruik maakt van moderne technologie.
De discussie is terecht. Het gebruik van algoritmes kent risico’s. Maar het lijkt niet goed te lukken om het gesprek over algoritmes genuanceerd en goed geïnformeerd te voeren. Alleen al het woord algoritme zorgt voor een soort verkramping in de discussie en lijkt de gebruiker ervan in het beklaagdenbankje te zetten. Als bedrijf dat de overheid helpt om datagedreven te werken, waren we ons vanaf het begin bewust van de risico’s en ontwerpen en ontwikkelen we op een verantwoorde manier oplossingen. Niet omdat de publieke opinie daarom vraagt, maar omdat we een eigen moreel kompas hebben.
Omdat we vaker vragen krijgen over de ethische kanten van het gebruik van algoritmes hebben we een aantal handvatten op een rij gezet. Geen doorgrond essay, of concreet raamwerk, maar een aantal ervaringen uit onze praktijk. Omdat we open zijn over hoe wij omgaan met de risico’s van het gebruik van algoritmes.
1. Gebruik geen voorspellende algoritmes (als het niet nodig is)!
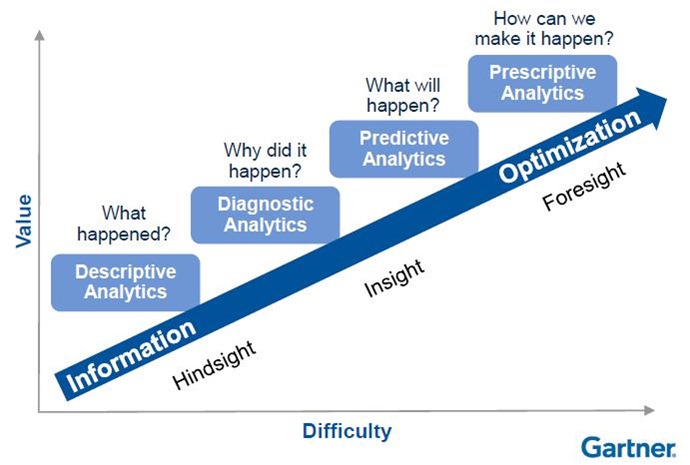
Ik geeft toe. Een beetje een dooddoener. Het begint natuurlijk bij de vraag: wat zijn voorspellende algoritmes? Ik ga er vanuit dat hiermee bedoeld wordt het begrip ‘predictive analytics’. Een methode waarmee veelal op basis van machine learning voorspellingen worden gedaan. Maar de wereld van data-analyse is breder dan alleen voorspellende algoritmes. Sterker nog: in onze praktijk zetten we predictive analytics vaak niet eens in. Zeker niet in onze oplossingen in het domein van toezicht & handhaving of veiligheid & openbare orde. Waarom niet? Omdat we geloven in ‘waardegestuurde’ ontwikkeling. Zie ook ons blog ‘Van datagestuurd naar waardegestuurd werken’. In het kort: zet het probleem en de gebruiker centraal en kijk van daaruit welke pijn het grootst is. Keer op keer blijkt dat de meeste waarde in eerste instantie wordt toegevoegd met een ‘beschrijvende analyse’. Niks voorspellingen op basis van machine learning dus, of in ieder geval niet vóór dat we weten waar de waarde zit, wat de feitelijke situatie is (beschrijvende analyse) en waar het probleem zit (diagnostisende analyse). Pas als aan die voorwaarden is voldaan kan er voorzichtig gekeken worden naar voorspellingen. Tot die tijd: gebruik geen voorspellende algoritmes!
Bron: Gartner
2. Wees transparant over data en modellen!
Zoals je in het artikel van de Volkskrant kunt lezen is een van de grootste obstakels bij SyRi dat voor de gebruiker niet duidelijk is op basis van welke datasets en indicatoren er een inzicht wordt verschaft. Omdat wij onze oplossingen ontwerpen vanuit gebruikersperspectief herkennen we hun behoefte om te weten op basis waarvan het systeem ergens een ‘rood puntje laat knipperen’. Zo zijn we voor de gemeente Zaanstad een data applicatie aan het ontwikkelen die de gemeente helpt bij het opsporen van o.a. woonfraude waarbij vanuit de applicatie inzichtelijk is welke datasets zijn gebruikt en op basis waarvan een indicatie wordt gegeven.
Screenshot prototype Ondermijning met beschrijving datasets en indicatoren
3. Gebruik indicatoren op basis van gedegen onderzoek!
Een veelgehoorde vrees is dat data-applicaties inzichten bieden die discrimineren. Data is immers niet objectief! Zeker bij het gebruik van ‘feedback loops’ zal een model leren op basis van ervaringen (data) uit het verleden en dat verleden bevestigen en versterken. Wat is dus een deugdelijk indicatie om bijvoorbeeld een pand te onderzoeken of daar iets mis is? Vaak vertalen we indicatoren van de (vak)mensen uit de praktijk naar het model maar proberen dat ook te onderbouwen door (wetenschappelijk) onderzoek. Zo hebben we met het RIEC Rotterdam een Risico Radar Ondermijning ontwikkeld waarbij Bureau Beke op basis van literatuuronderzoek en expert interviews een lijst van 52 indicatoren samengesteld die wij hebben gebruikt om zicht te krijgen op risico’s op ondermijning door bedrijven. In september organiseren we samen met het RIEC en Bureau Beke een webinar waarin we hier meer over vertellen. Zijn deze indicatoren daarmee allemaal 100% objectief? Nee, maar wel binnen de normen van de (gedrags-)wetenschap als significant bestempeld.
Jurriaan Souer (Shintō Labs) in actie met dr. Henk Ferwerda van Bureau Beke, onderzoeksbureau voor criminologische vraagstukken
4. Laat systemen niet beslissen, maar help de expert!
Er zijn (soms schrijnende) voorbeelden van Kafkaëske situaties waarbij de overheid besluiten neemt waar de mens geen grip meer op heeft. ‘Computer says no.’ De angst is dat voorspellende algoritmes besluiten nemen zonder dat er een mens aan te pas komt. Als ik dan roep dat zoiets nooit moet kunnen, dan zegt mijn collega Jurriaan relativerend tegen me: ‘Dus ook niet bij slimme vuilnisbakken die automatisch opdracht geven aan de vuilnisophaaldienst om geleegd te worden?’. Tja, daar natuurlijk wel. Maar in onze praktijk komt het zelden voor dat gebruikers één antwoord willen, laat staan een geautomatiseerd besluit. Ze willen een instrument dat ze helpt om op basis van hun eigen expertise makkelijker of sneller inzicht te krijgen dan nu het geval is. We kennen voorbeelden van beleidsambtenaren uit het veiligheidsdomein die na een melding soms anderhalve dag kwijt zijn om in 15 systemen te kijken om te bepalen of er iets aan de hand is. Het enige dat we doen is de data sneller aanleveren dan nu en deze zodanig visualiseren dat de expert kan besluiten om al dan niet tot actie over te gaan. We helpen dus bij het maken van een risico inschatting.
5. Realiseer je dat ‘bias’ in de mens zit en daarmee ook in de data
Tijdens onze Design Sprints, het startpunt van onze ontwikkeling, nemen we veel tijd om gebruikers te laten vertellen over het vraagstuk. We willen weten hoe ze daar nu mee omgaan, dus zonder data-analyse en algoritmes. Als wij met mensen uit de wereld van toezicht en handhaving praten en ze vragen waar risico op een overtreding is, dan kunnen ze zo een lijstje van risicoindicatoren oplepelen. Hoe ze daarbij komen? Ervaring. Als jij bij controles meerdere keren fraude aantreft bij een bepaald soort bedrijven dan word je als handhaver alerter en controleer je vaker bij dat soort bedrijven. Is dat terecht? Misschien wel, misschien niet. In iedere geval heel menselijk. Dataprojecten versterken niet de bias. Ze leggen die juist bloot.
Bron: https://dilbert.com/
Tot slot
Ik zat laatst het radioprogramma BNR Digitaal te luisteren toen ik Rudy van Belkom hoorde zeggen: ‘We hebben het altijd over ‘explainable AI’ maar hoe ‘explainable’ is menselijk gedrag eigenlijk?’ Een mooi inzicht wat mij betreft. Geen complexer neuraal netwerk dan het menselijk brein. Discriminatie is een product daarvan. Laten we ons dus met of zonder algoritmen daarvan bewust blijven. Waar het om gaat, is dat we de uitwassen tot een minimum beperken.
P.s. binnenkort zal onze Chief Data Scientist Eric een vervolg op dit blog schrijven hoe we in technische zin het risico op ‘bias’ proberen te minimaliseren. Wil je automatisch bericht ontvangen via email als dat blog verschijnt? Schrijf je dan hier in.
https://www.shintolabs.nl/wp-content/uploads/2019/07/alexandra-gorn-smuS_jUZa9I-unsplash.jpg14994005Bart Rossieauhttps://www.shintolabs.nl/wp-content/uploads/2016/09/Logo_Shinto_Labs_156h-300x152.pngBart Rossieau2019-07-05 22:35:182019-07-11 11:18:415 praktische handvatten om ‘algoritmekramp’ tegen te gaan